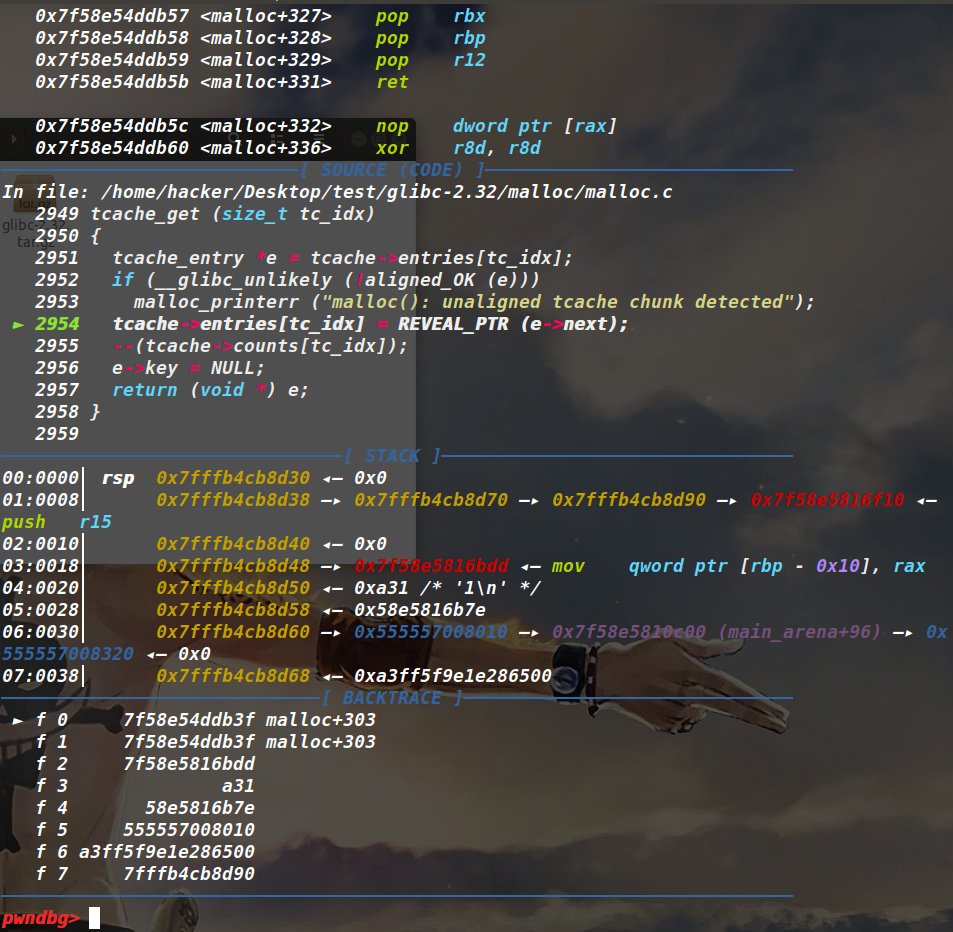
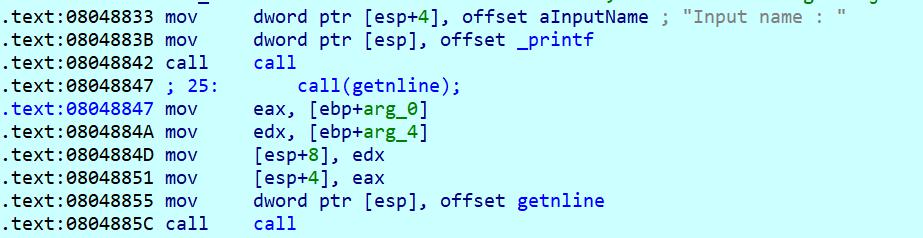
typedef struct { void *tcb; /* Pointer to the TCB. Not necessarily the thread descriptor used by libpthread. */ dtv_t *dtv; void *self; /* Pointer to the thread descriptor. */ int multiple_threads; int gscope_flag; uintptr_t sysinfo; uintptr_t stack_guard;//即为canary,fs:28h处 uintptr_t pointer_guard; ... } tcbhead_t;
// Open and map I/O memory for the strng device int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0", O_RDWR | O_SYNC);//这里需要获取到mmio的地址 if (mmio_fd == -1) die("mmio_fd open failed");
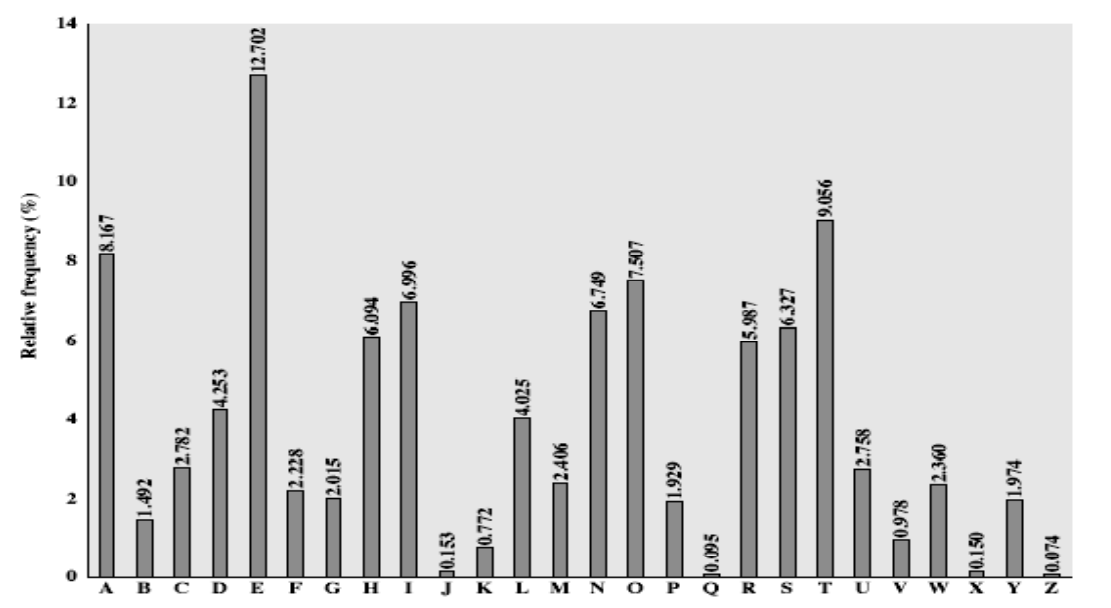
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
7 14 11 3 7 14 11 3 7 14 11 3 7 14 11 3 7 14 key: H O L D H O L D H O L D H O L D H O plaintext: T H I S I S T H E P L A I N T E X T 19 7 8 18 8 18 19 7 4 15 11 0 8 13 19 4 23 19
相加mod26: 0 21 19 21 15 6 4 10 11 3 22 3 15 1 4 7 4 7 ciphertext: A V T V P G E K L D W D P B E H E H
以上两种方法都可以。
☆分析:
算密钥长度:一段密文中查找重复出现的几个字节,计算重复出现的几个
1 2 3 4 5
//注释头
key: R U N R U N R U N R U N R U N R U N R U N R U N R U N plaintext: T O B E O R N O T T O B E T H A T I S T H E Q U E S T ciphertext: K I O V I E E I G K I O V N U R N V J N U V K H V M G
if doc.status_code != 200: winsound.Beep(2000, 2000) print("无法访问") time.sleep(10) continue
json_dict = json.loads(doc.text) data = json_dict["data"] for attack in data: ip = attack["name"] hasRisk = ( int(attack["middle"]) > 0 or int(attack["high"]) > 0 or int(attack["critical"]) > 0 )
connect(ui->btnListen,&QPushButton::clicked,[this]{ //if Listening,close it if(server->isListening()){ //server->close(); closeServer();//Define function //Recover the status after closed }else{ const QString address_text=ui->editAddress->text(); const QHostAddress address=(address_text=="Any") ?QHostAddress::Any :QHostAddress(address_text); constunsignedshort port=ui->editPort->text().toUShort(); if(server->listen(address,port)){ //handle function }else{ //error function } } }
(3)检测到连接,开始处理:
1 2 3 4 5 6 7 8 9 10 11 12 13
//注释头
connect(server,&QTcpServer::newConnection,this,[this]{ while(server->hasPendingConnections()) { //nextPendingConnection get the next obj QTcpSocket *socket=server->nextPendingConnection(); clientList.append(socket); ui->textRecv->append(QString("(%1:%2) Soket Connected") .arg(socket->peerAddress().toString()) .arg(socket->peerPort())); ui->textRecv->append(recv_text); });
















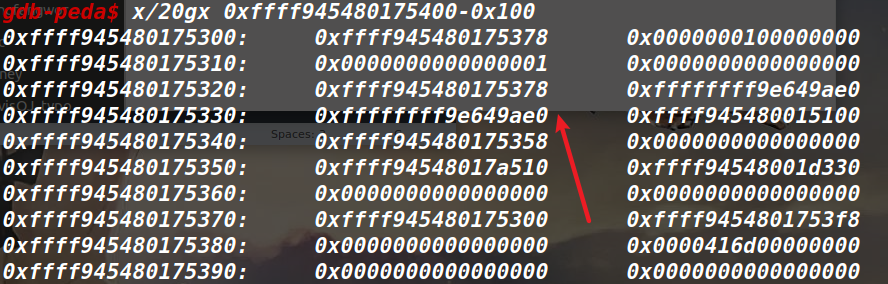
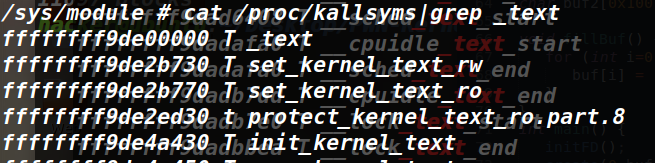


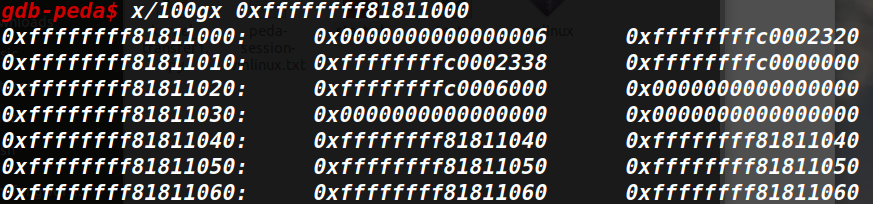







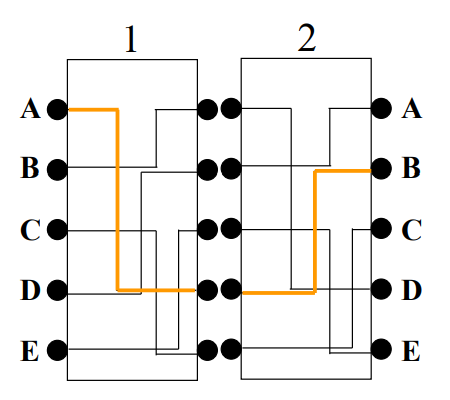
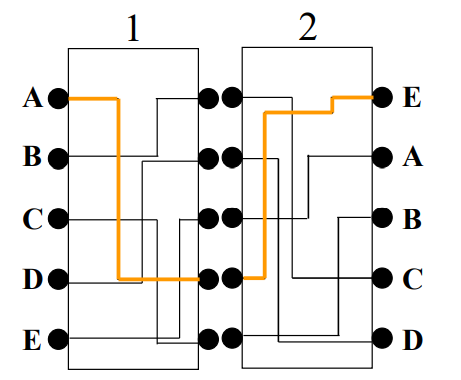



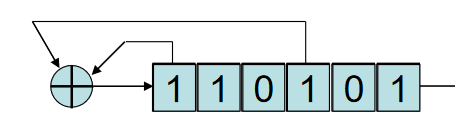

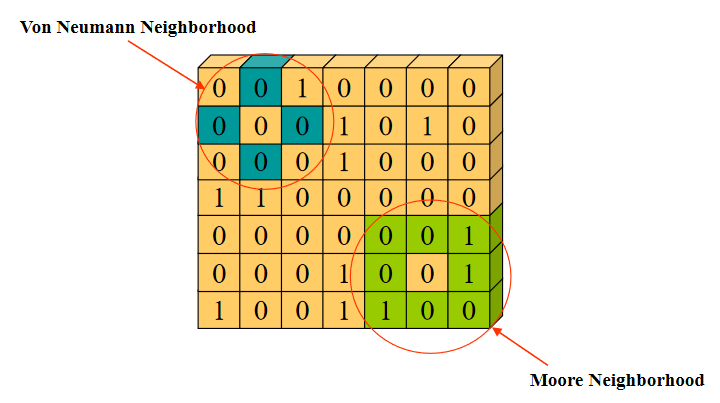
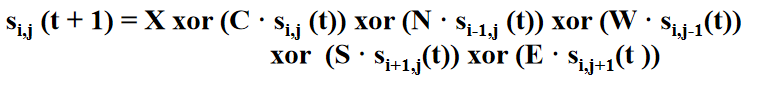
 第一次(只知道密文Ci)
第一次(只知道密文Ci) 第二次插入p后(知道密文Ci和p、c)
第二次插入p后(知道密文Ci和p、c)