C++程序用IDA打开好多都不能将switch识别成功,常常需要修复:
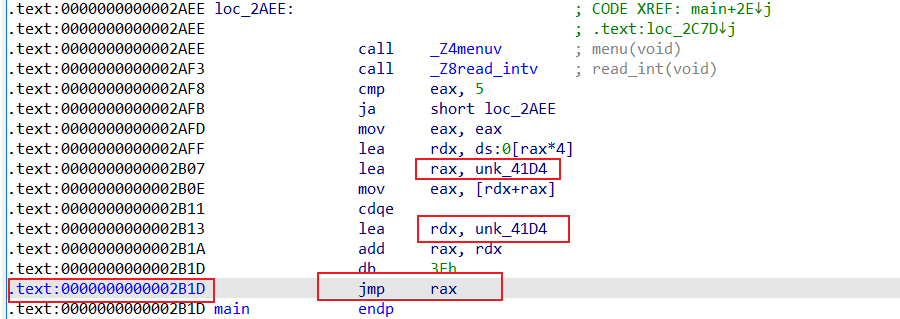
常常反汇编之后如下,这个基本就是无法识别switch的时候了
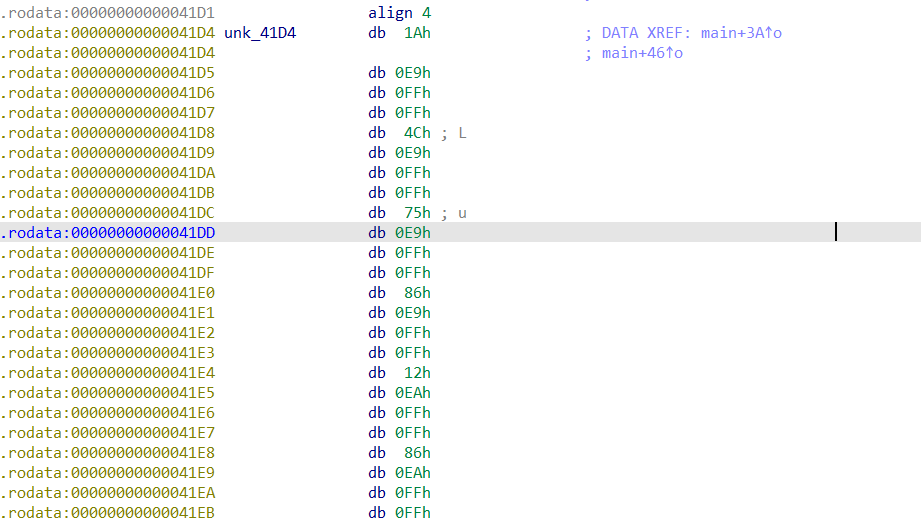
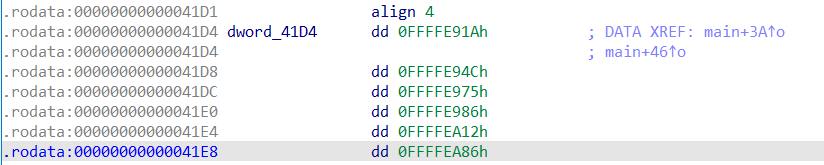
进入到unk_41D4 ,里面放着对应的跳转数据
按d以4字节为一组对应修改为如下,可见跳转数量有6个
然后对应修改数据
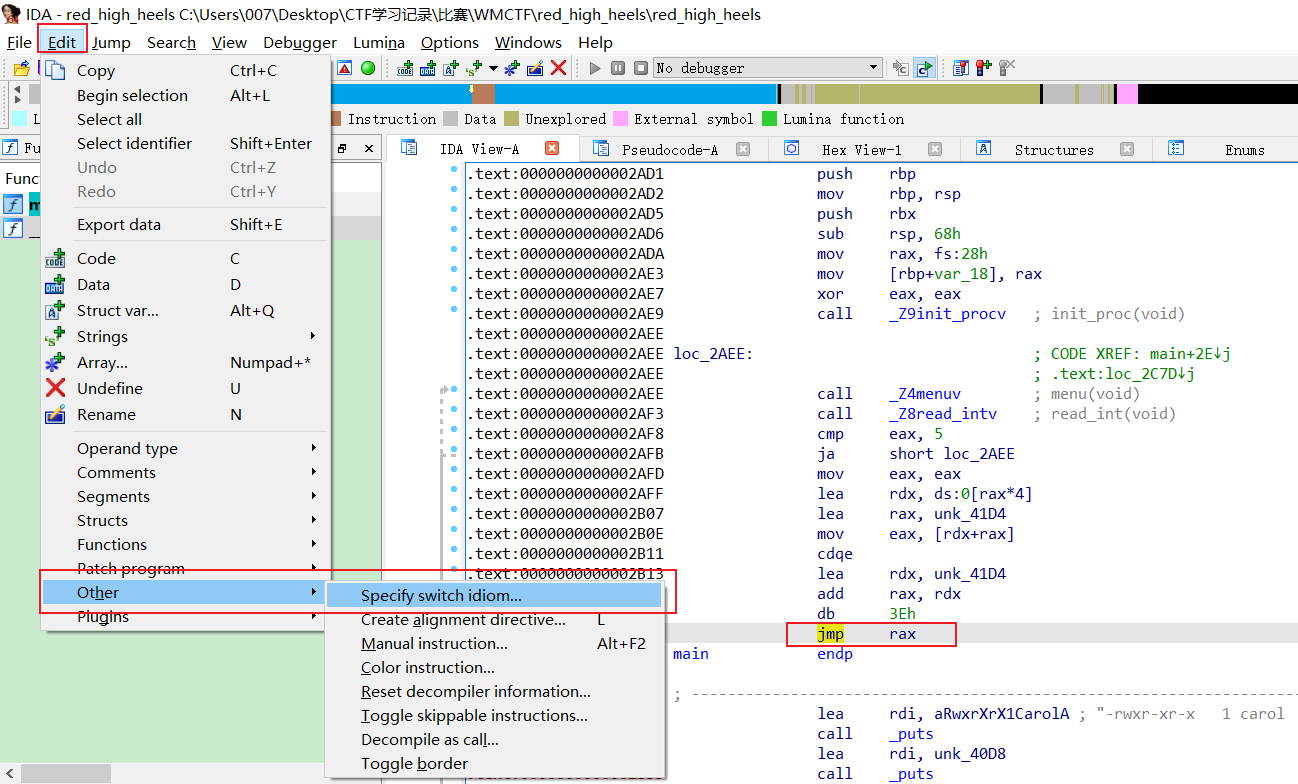
Edit->Other->Specify switch idiom
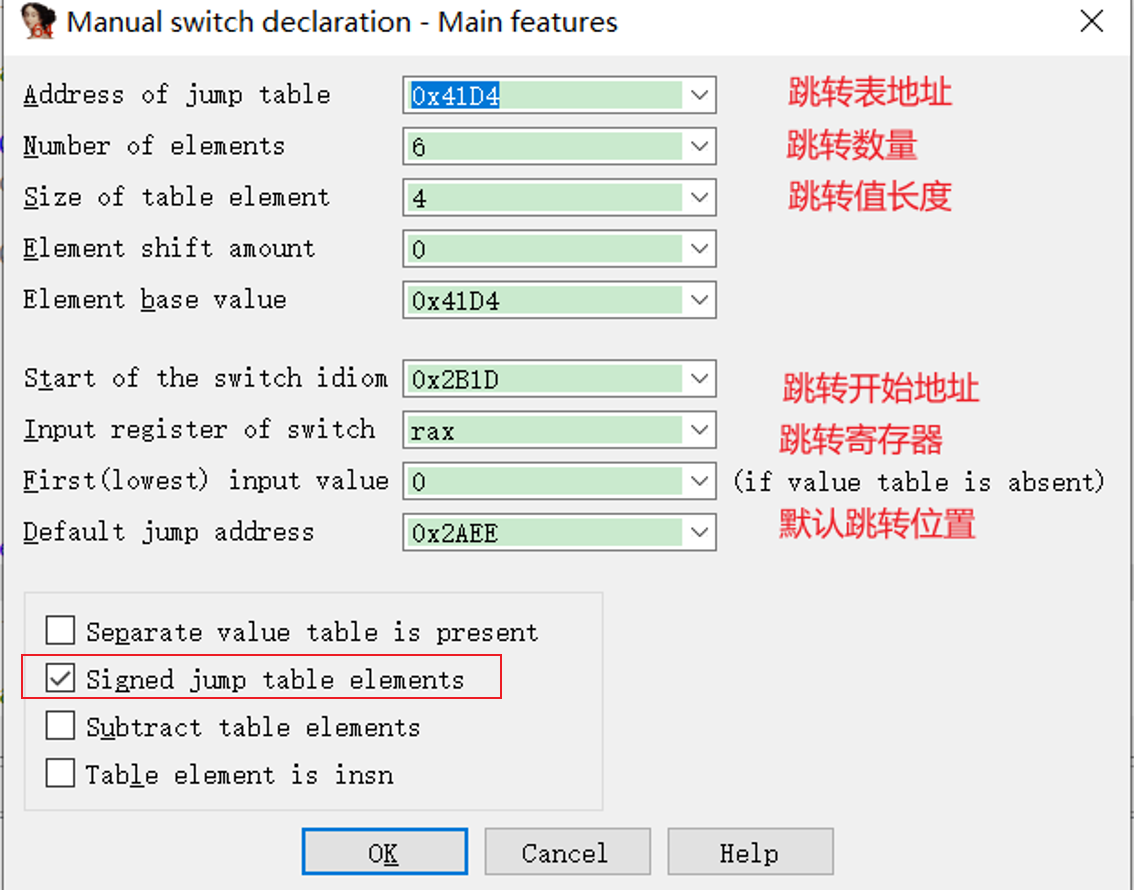
打开之后修改对应数据
其中默认跳转位置可以通过调试看输入其他的选项的跳转位置。
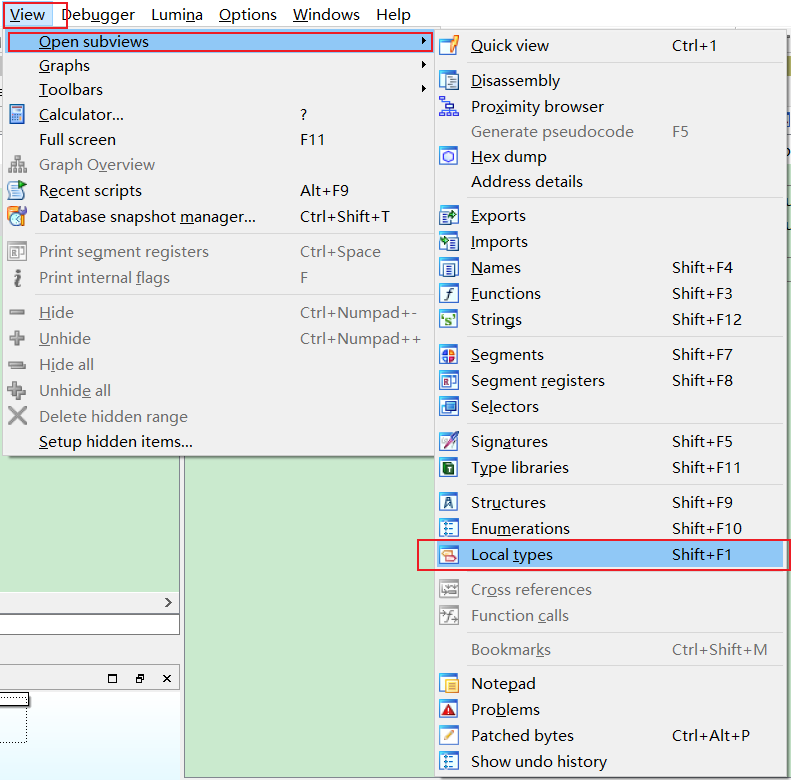
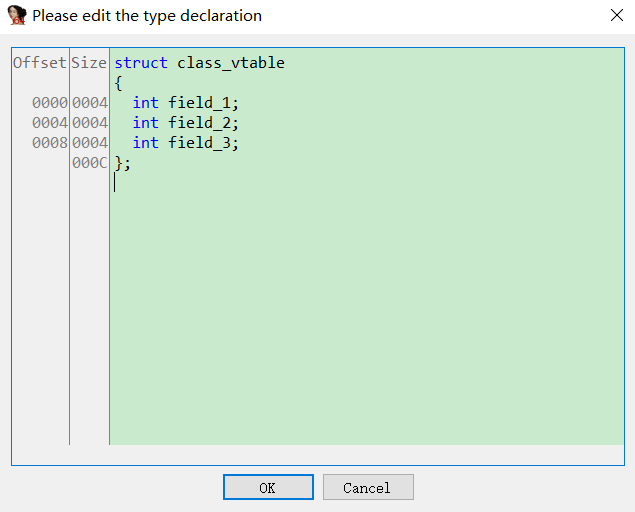
View->Open subviews->Local_types
右键Insert输入对应结构体即可
在对应变量按y修改为对应指针
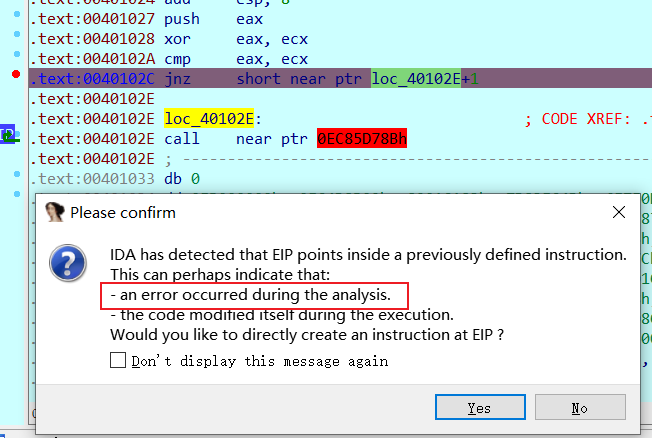
IDA中调试出现如下错误,或者观察也知道
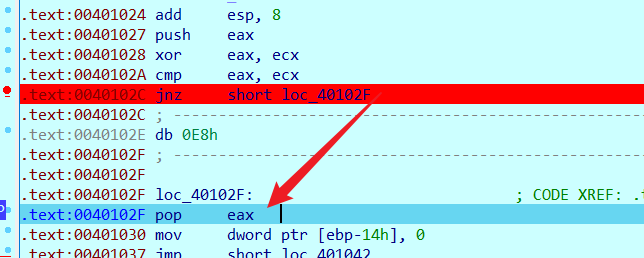
这时候可能出现花指令,使得IDA无法正常识别,再往下走IDA跳转到0x40102f,则证明0x40102c~0x40102e这三个字节码都是无效的,直接nop掉,然后patch之后重新打开IDA即可正常识别
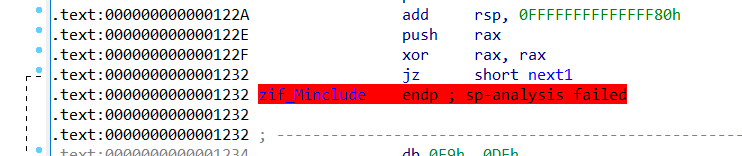
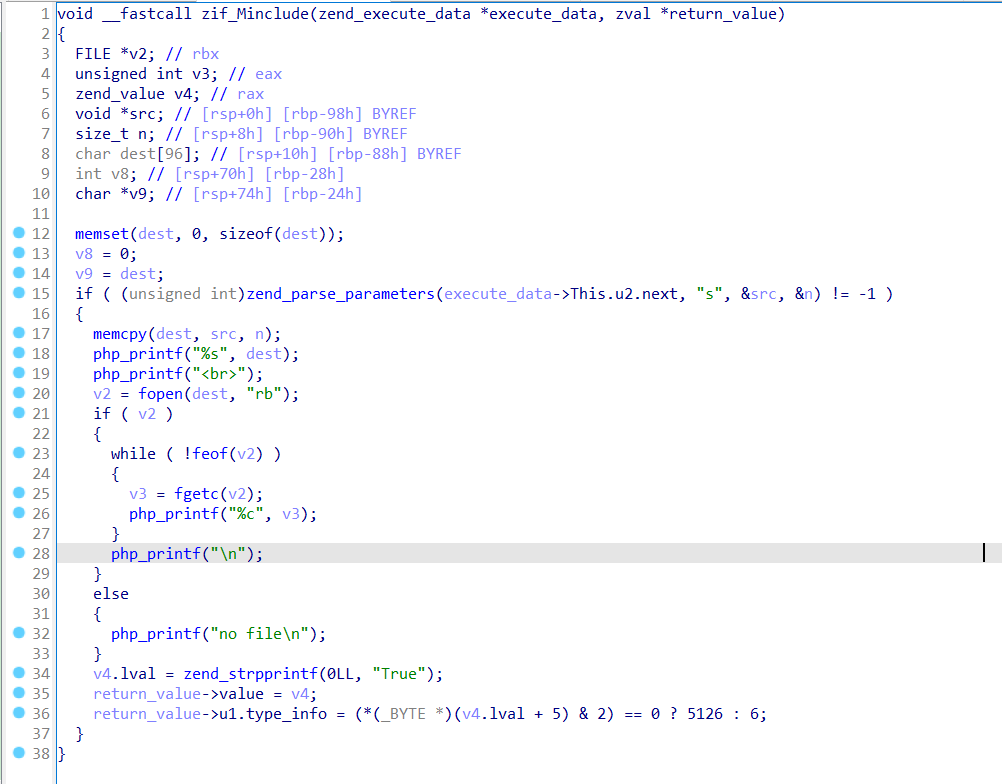
以2020De1CTF-mixture为例,IDA打开找到zif_类函数,可以看到堆栈指针问题
那么可能存在花指令或其他的影响,可以参考如下两种方法
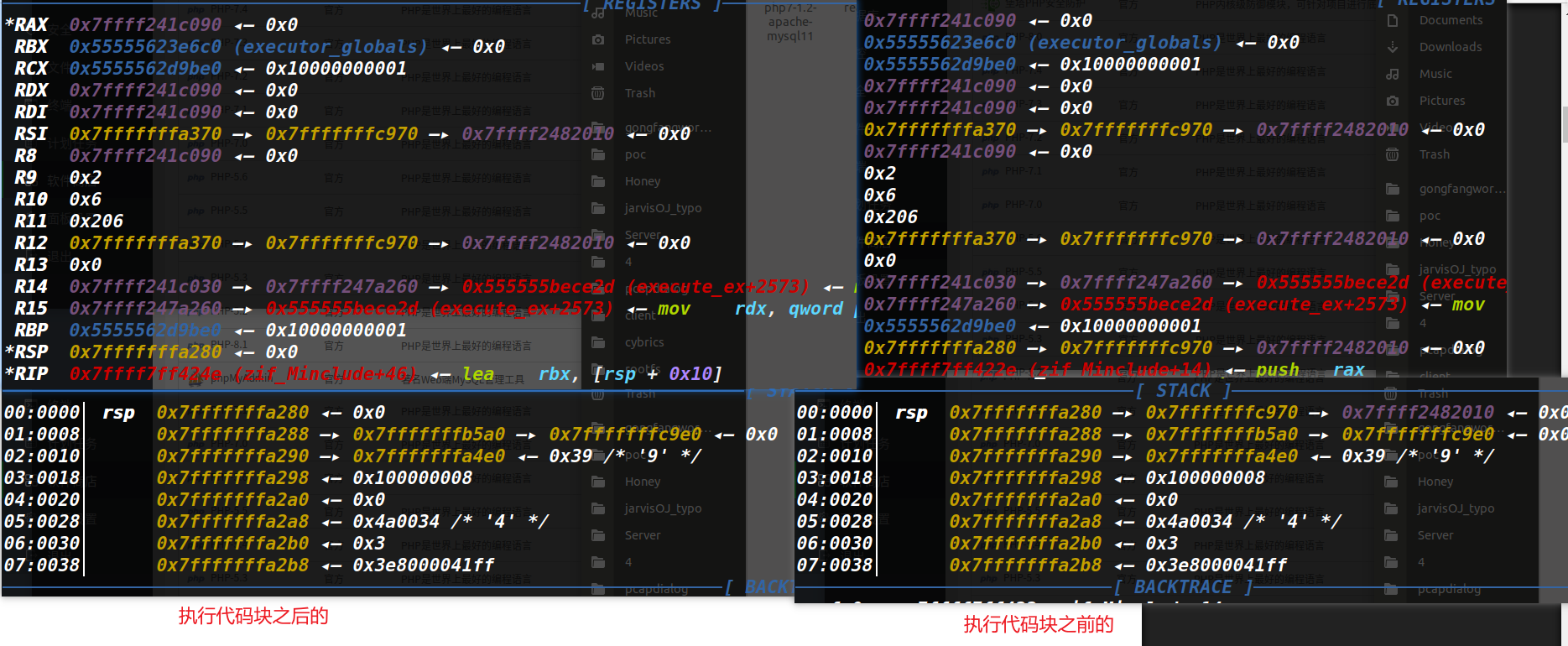
首先考虑调试看看堆栈寄存器的变化,如下
可以看到,在执行从0x122E~0x124D这个代码块之前和之后的寄存器除了rip其他都没有改变。
栈环境除了rsp的值被改变了其他的没有什么影响,而对于栈来说,主要就是栈指针的移动和传入参数的压栈,首先栈指针并没有发生改变,在考虑传入参数的压栈。
传入的参数为如下两个参数rdi和rsi,并且最开始的汇编代码并没有对rdi和rsi进行操作,那么这段代码块就等于无效,相当于就是一个jz 0x124e,那么我们直接给他nop掉即可
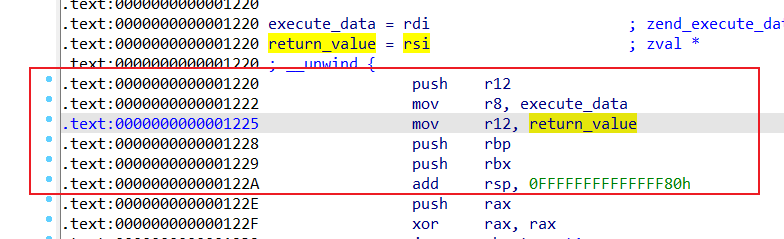
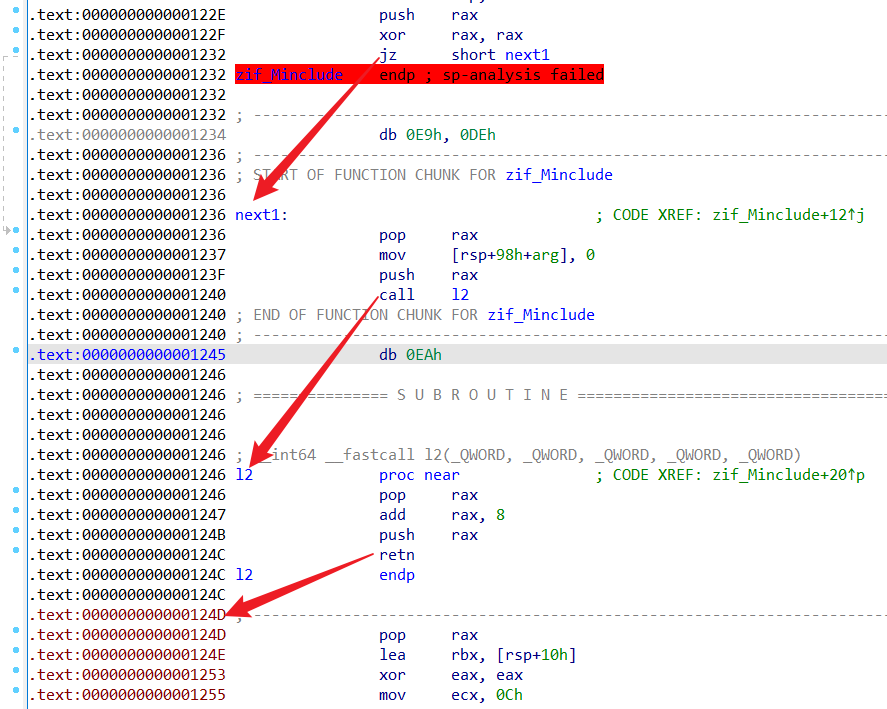
0x122e~0x124d如下
可以发现,call l2之后,l2函数通过rax把l2函数的返回地址+8了,也就是从0x1245变成了0x124d,那么就等同于如下代码
1 2 3 4 5 6 7 8 9 .text:000000000000122E push rax .text:000000000000122F xor rax, rax .text:0000000000001236 pop rax .text:0000000000001237 mov [rsp+98h+arg], 0 .text:000000000000123F push rax .text:000000000000124D pop rax
这不就相当于啥也没做吗,只是有个mov [rsp+98h+arg], 0操作而已,但是也不影响参数,等同没有。
之后的0x131E~0x132D也是一样的错误,直接nop掉即可。之后即可正常F5
虎符杯2022 gogogo
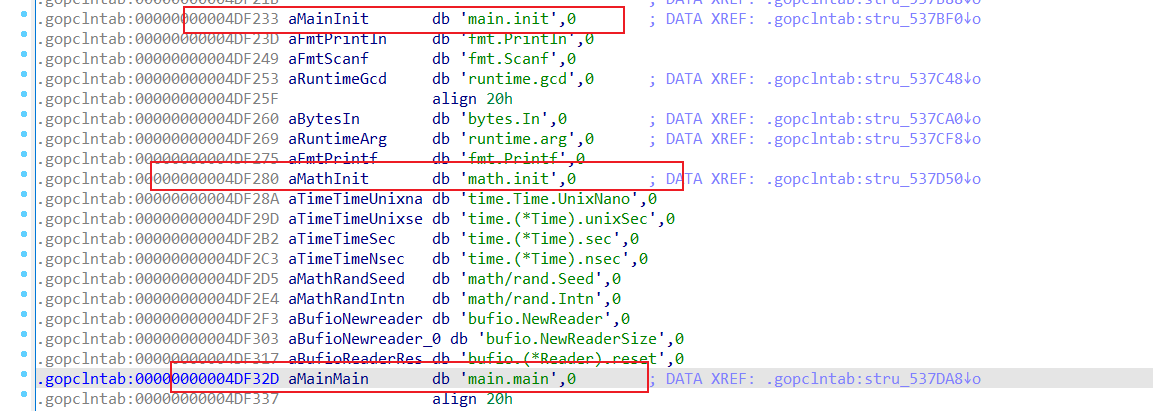
现有插件或者IDA7.6对go的符号恢复是基于gopclntab段上保留的函数符号,那么如果将该段上的符号函数进行修改或者隐藏,就不太容易逆向了
该题就是将main.main和math.init符号表替换,然后在main.main中设置一些原本main函数输入0x12345678退出的功能,使得逆向时我们认为main.main函数就只有这个功能,并没有其他功能,导致无法进行漏洞分析,修改回来就可以了,直接改这个表.gopclntab即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class A { public : A (){ printf ("A::A()\n" ); id = 42 ; } virtual void a () printf ("Virtual A::a()\n" ); } virtual ~A (){ printf ("A::~A()\n" ); } private : int id; }; class B :public A { public : B (){ printf ("B::B()\n" ); } virtual ~B (){ printf ("B::~B()\n" ); } virtual void a () printf ("Virtual B::a()\n" ); A::a (); } virtual void b () printf ("Virtual B::b()\n" ); A::a (); } };
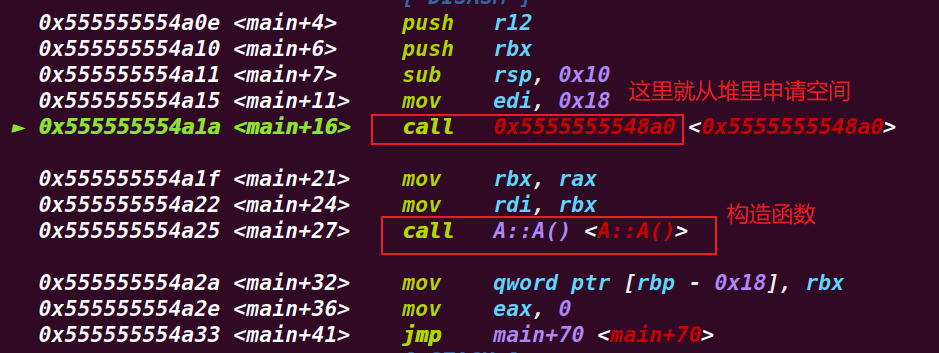
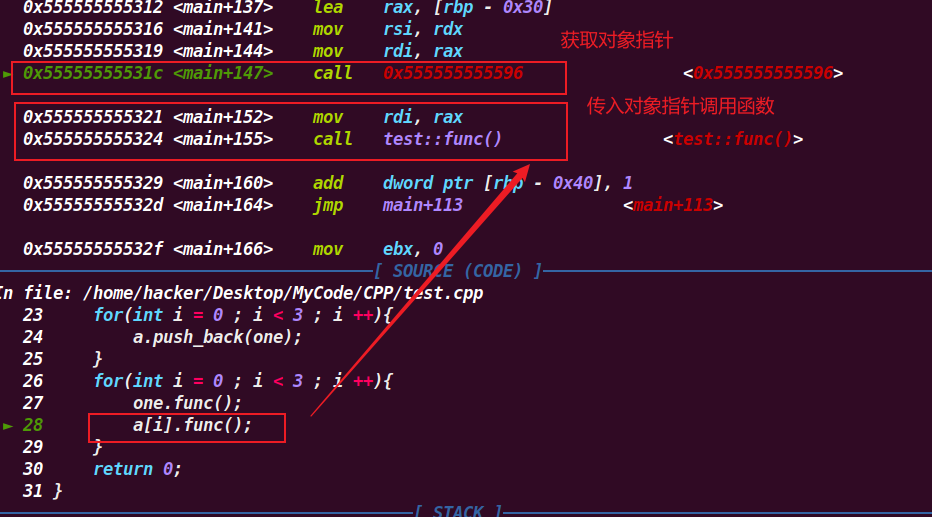
用上述代码的class A来举例
在调用构造函数A::A()之前会从堆里申请一块空间,即class A的空间,包括指针和成员。
在A::A()构造函数调用之后会初始化该堆空间,申请的堆空间如下。
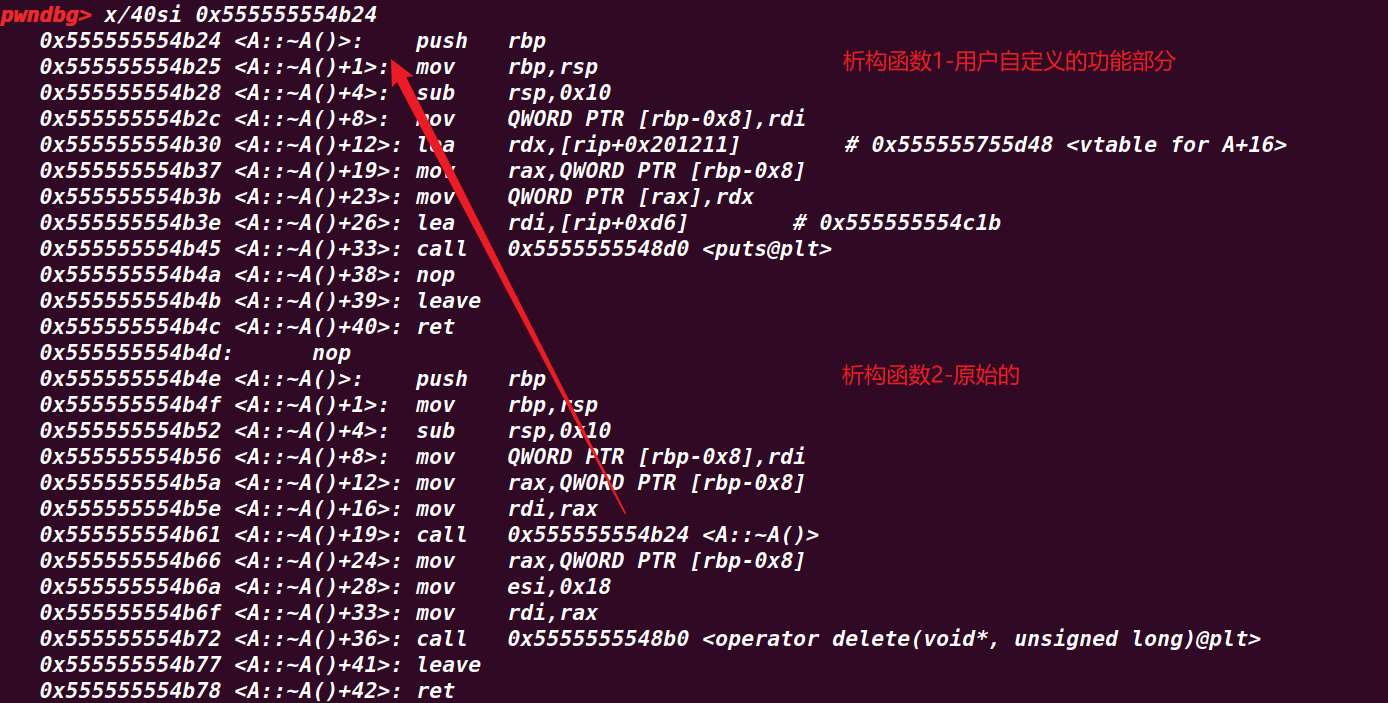
然后还需要注意的是有两个函数指针,析构函数指针1和析构函数指针2,其中析构函数指针2是实际的用来释放空间的函数,即原始的析构函数,并且其中会调用到析构函数指针1,即用户自定义的析构函数相关的代码,并且地址是连在一起的,如下所示。
以上述代码的class B来举例
其他的和没有父类的class也是差不多的。
比如A obj_a;这种写法,那么其public的成员会变成栈上的变量,private成员无法访问,访问其成员函数还是在.text段上对应的。
A *point_obj_A = new A; :会调用A的构造函数
A *point_obj_A = new(A); :同上,一样的
A obj_A; :A的构造函数调用之后,如果没有其他的操作,那么程序会自动释放该对象,调用析构函数,相当于局部变量。
B *point_obj_b = new B;会先调用A的构造函数,然后再调用B的构造函数,和前面的指针没有太多关系,直接B obj_B也是一样的
A *point_obj_b = new B;一样的,只是将point_obj_b 标记为类型为A的指针,但是这样的话该对象指针point_obj_b就不能调用到子类B的函数b()了。(子类指针可以调用父类的函数,但是父类指针不能调用子类的特有函数)
参考:C++逆向之容器vector篇入门 - 安全客,安全资讯平台 (anquanke.com)
1 2 3 4 vector <int > test1;std ::vector <int >::vector (v8, argv, envp);
这个不造成堆空间的分配
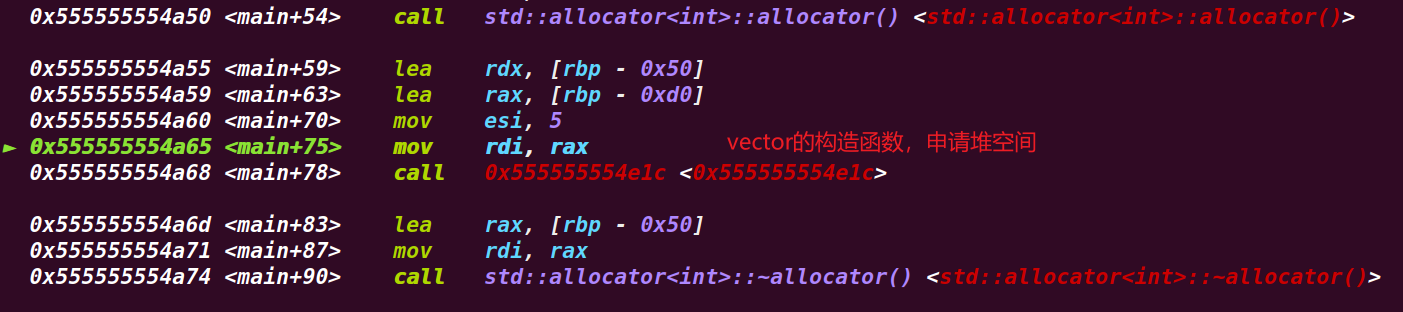
1 2 3 4 5 6 vector <int > test2 (5 ) std ::allocator<int >::allocator(v13);std ::vector <int >::vector (v9, 5LL , v13);std ::allocator<int >::~allocator(v13);
这个在调用vector的构造函数时,会有堆空间的申请,用来存放容器内的数据,依据定义的大小来进行申请,比如这里就申请了5个int的变量,那么大小为5*4=20个字节,对应在堆空间里就需要申请0x20大小的堆块来存放。
使用malloc来申请
容量+初始值模式
1 2 3 4 5 6 7 vector <int > test3 (10 ,1 ) std ::allocator<int >::allocator(v12);v13[0 ] = 1 ; std ::vector <int >::vector (v10, 10LL , v13, v12);std ::allocator<int >::~allocator(v12);
可以看到也是类似的,会创建一个局部变量v13作为初始值1传入vector的构造函数,并且申请堆空间后会进行初始化,所需大小为10*4=40个字节,对应0x30的堆空间,并且会初始化为1,如下所示。
相关寄存器如下
Begin+End模式
这里区别于之前的传值,即容量的值以及初始值的地址,取而代之的是数据的起始地址和结束地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 vector <int > test5 (test3.begin(), test3.end()) getchar(); int array [5 ] = {1 , 2 , 3 , 4 , 5 };vector <int > test6 (&array [1 ], &array [4 ]) getchar(); ---------------------------------------------------------------------- std ::allocator<int >::allocator(v17, 1LL , v5);v6 = std ::vector <int >::end(v14); v7 = std ::vector <int >::begin(v14); std ::vector <int >::vector <__gnu_cxx::__normal_iterator<int *,std ::vector <int >>,void >(v16, v7, v6, v17);std ::allocator<int >::~allocator(v17);getchar(); v17[8 ] = 1 ; v18[0 ] = 2 ; v18[1 ] = 3 ; v18[2 ] = 4 ; v19 = 5 ; std ::allocator<int >::allocator(&v10, v7, v8);std ::vector <int >::vector <int *,void >(v17, v18, &v19, &v10);std ::allocator<int >::~allocator(&v10);getchar();
相关寄存器如下
栈上的数组模式
主要就是关注vector的构造函数
1 2 3 4 5 6 std ::vector <int >::~vector (v17);std ::vector <int >::~vector (v16);std ::vector <int >::~vector (v15);std ::vector <int >::~vector (v14);std ::vector <int >::~vector (v13);std ::vector <int >::~vector (v12);
主要关注push_back和pop_back
这里就存在漏洞了,就是如果接着pop会导致End不断减少,当小于Begin的地址时,这时候再push_back的话,就会在小于Begin地址处写入数据,导致堆块数据被重写,如下:
1 2 3 4 5 6 7 8 9 10 vector <int > test;for (int i=0 ; i<2 ; i++) test.push_back(i); getchar(); for (int i=0 ; i<10 ; i++) test.pop_back(); getchar(); test.push_back(0x50 );
这样就会导致上一个堆块的数据被覆盖为0x50
此时再push_back(0x50),会如下
就导致漏洞产生了。
相关的IDA代码如下
1 2 3 4 5 6 7 8 9 std ::vector <int >::vector (v11, argv, envp);for ( v12[0 ] = 0 ; v12[0 ] <= 1 ; ++v12[0 ] ) std ::vector <int >::push_back(v11, v12); getchar(); for ( i = 0 ; i <= 9 ; ++i ) std ::vector <int >::pop_back(v11); getchar(); v12[0 ] = 80 ; std ::vector <int >::push_back(v11, v12);
这个还是挺简单的,就不说了。
其他的像empty()、resize()、clear()什么的也是类似的,不多说了。
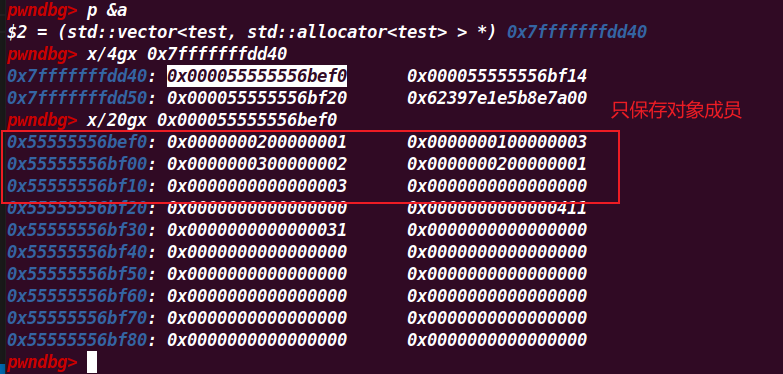
🔺注
对于类class放入vector的情况,在vector中只会保存对象的成员变量,而它的函数指针并不会保存
当从容器中取出来时,会通过一个函数来获取对应成员的地址,之后传入对应的函数。
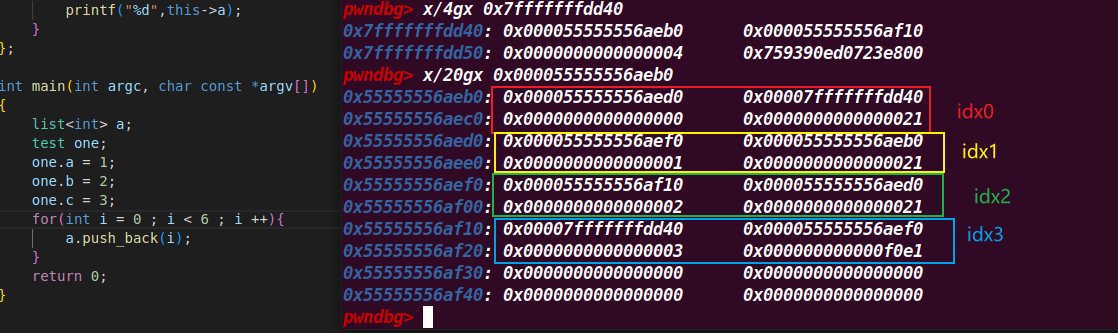
常见双向循环链表管理
双向循环链表,定义之后栈上只保存头节点地址和尾部节点地址
每次申请push_back加入对象时都会使用malloc申请,创建next、prev指针,然后拷贝数据,将其放入双向循环链表中
cq674350529/deflat: use angr to deobfuscation (github.com)
以上类型的就是平坦化之后的,需要找到函数入口进行去除,之后即可得到去除后的
1 python3 deflat.py -f binary --addr 0x400530
使用代码查找内存,找到混淆的地方,然后通过avoid来去除
1 2 3 4 5 6 7 8 9 10 11 12 binary = open ('./yolomolo' , 'rb' ).read() avoids = [] index = 0 while True : index = e.find(b'\xB9\x00\x00\x00\x00' ,index+1 ) if index == -1 : break addr = 0x400000 + index avoids.append() print (len (avoids))print (avoids)
查找内存中的机器码为'\xB9\x00\x00\x00\x00'的地方,即mov ecx 0,这个为一些混淆的标志。
即找到混淆的标志点,然后通过avoid来去除。
1 2 3 4 from idc_bc695 import *addr = 0x401807 for i in range (0x401823 -0x401807 ): PatchByte(addr +i, Byte(addr+i)^0x90 )
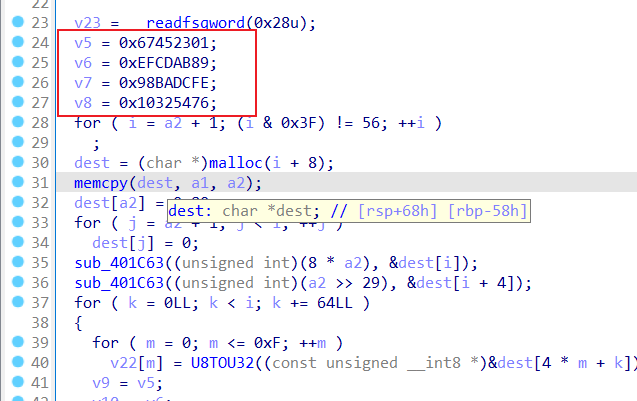
标识符:0x123456789
常见形式如下
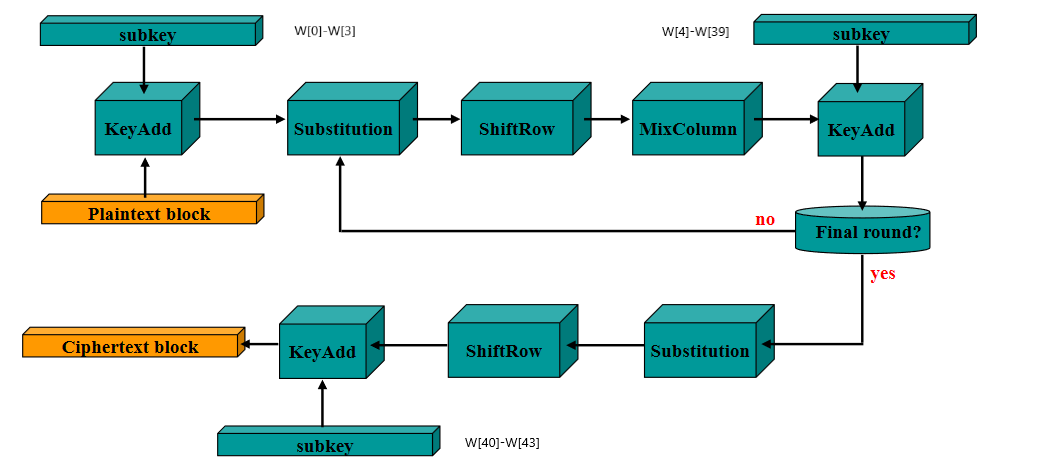
首先轮密钥加(KeyAdd)
9轮循环:字节替换(substitution)、行移位(ShifRow)、列混淆(MixColumn)、轮密钥加(KeyAdd)
第10轮循环:字节替换(substitution)、行移位(ShifRow)、轮密钥加(KeyAdd)
第十轮没有列混淆,加密过程常见如下,函数名称是用Finger识别的
先for循环4次,再for循环40次,属于密钥扩展
如果密文的长度是16字节的整数倍,并且没有任何重复的块,那么可能是CTR或OFB模式3。https://blog.csdn.net/qq_41853048/article/details/131771420
1 2 3 4 5 6 7 8 9 10 11 12 13 import refrom Crypto.Cipher import AESfrom binascii import b2a_hexmode = AES.MODE_ECB key = b'\xcb\x8d\x49\x35\x21\xb4\x7a\x4c\xc1\xae\x7e\x62\x22\x92\x66\xce' text = b'\xBC\x0A\xAD\xC0\x14\x7C\x5E\xCC\xE0\xB1\x40\xBC\x9C\x51\xD5\x2B\x46\xB2\xB9\x43\x4D\xE5\x32\x4B\xAD\x7F\xB4\xB3\x9C\xDB\x4B\x5B' cryptos = AES.new(key, mode) cipher_text = cryptos.decrypt(text) t = b2a_hex(cipher_text).decode() t = re.findall(".{2}" , t) for x in t: print (chr (int (x, 16 )), end="" )
几个常见模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 from z3 import * a1 = [] for i in range (33 ): a1.append(BitVec('a1%d' % i, 8 )) s = Solver() s.add(And((a1[5 ] ^ (a1[8 ] * a1[8 ] - a1[1 ]) ^ 0x33 ) == 9600 , ((a1[30 ] + a1[27 ] + a1[24 ] + a1[11 ] - a1[12 ] - a1[0 ] * a1[15 ] * a1[7 ]) ^ 0x64 ) == -344791 , ((a1[8 ] + a1[16 ] * a1[29 ] * a1[1 ] - a1[25 ]) ^ 0x62 ) == 406716 , ((a1[4 ] - a1[1 ]) ^ (a1[0 ] * a1[31 ] + a1[28 ] - a1[26 ]) ^ a1[13 ] ^ 0x66 ) == -8688 , ((a1[13 ] + a1[18 ] + a1[3 ] * a1[7 ] - a1[23 ] - a1[3 ]) ^ 0x66 ) == 3085 , ((a1[18 ] - a1[1 ] * a1[29 ]) ^ (a1[30 ] + a1[22 ] - a1[1 ]) ^ a1[15 ] ^ (a1[2 ] * a1[31 ]) ^ 0x35 ) == -16248 , ((a1[3 ] * a1[21 ] + a1[29 ] + a1[25 ] + a1[4 ] * a1[23 ] - a1[2 ] * a1[7 ] - a1[21 ]) ^ 0x65 ) == 4469 , ((a1[3 ] + a1[1 ] - a1[2 ]) ^ (a1[23 ] * a1[23 ]) ^ 0x61 ) == 2761 , ((a1[5 ] * a1[11 ]) ^ (a1[8 ] * a1[21 ]) ^ a1[29 ] ^ 0x39 ) == 7832 )) s.add(And(((a1[7 ] * a1[11 ] * a1[8 ] + a1[14 ]) ^ (a1[10 ] + 2 * a1[25 ]) ^ (a1[10 ] * a1[15 ]) ^ 0x61 ) == 234968 , (a1[8 ] ^ (a1[19 ] + a1[27 ] + a1[19 ] * a1[0 ] + a1[9 ] * a1[25 ]) ^ a1[28 ] ^ a1[7 ] ^ 0x30 ) == 11738 , ((a1[32 ] - a1[1 ]) ^ (a1[28 ] + a1[14 ] - a1[2 ] * a1[21 ]) ^ a1[21 ] ^ 0x38 ) == 3252 , ((a1[1 ] * a1[32 ]) ^ (a1[8 ] + a1[0 ] - a1[5 ] - a1[11 ]) ^ a1[21 ] ^ (a1[2 ] - a1[12 ]) ^ 0x32 ) == -2673 , (a1[2 ] ^ (a1[0 ] + a1[1 ]) ^ (a1[6 ] - a1[19 ] - a1[22 ]) ^ 0x64 ) == -164 , ((a1[25 ] - a1[0 ]) ^ (a1[28 ] + a1[4 ] + a1[31 ] * a1[31 ] + a1[2 ] - a1[32 ]) ^ 0x30 ) == -15811 , (a1[6 ] ^ (a1[5 ] + a1[15 ] * a1[32 ] - a1[32 ] * a1[19 ] * a1[22 ]) ^ a1[8 ] ^ 0x61 ) == -167332 , ((a1[26 ] + a1[32 ] * a1[24 ] - a1[10 ]) ^ (a1[11 ] * a1[3 ] - a1[30 ] - a1[27 ] - a1[31 ]) ^ 0x64 ) == 3470 , ((a1[5 ] * a1[15 ]) ^ (a1[18 ] * a1[25 ] + a1[14 ] + a1[2 ] + a1[26 ] + a1[27 ]) ^ a1[29 ] ^ 0x38 ) == 4323 , ((a1[29 ] * a1[8 ] * a1[21 ] * a1[27 ] + a1[13 ] - a1[7 ]) ^ a1[5 ] ^ 0x39 ) == 25234850 )) s.add(And(((a1[0 ] * a1[8 ] * a1[13 ] + a1[6 ] + a1[19 ] * a1[23 ] - a1[2 ]) ^ 0x62 ) == 394534 , ((a1[14 ] + a1[30 ] + a1[14 ] - a1[30 ] - a1[2 ] * a1[30 ] * a1[1 ] * a1[17 ] - a1[2 ]) ^ 0x35 ) == -15531747 , ((a1[1 ] * a1[14 ]) ^ (a1[13 ] - a1[27 ] * a1[32 ]) ^ 0x33 ) == -9992 , (a1[11 ] ^ a1[25 ] ^ a1[12 ] ^ a1[2 ] ^ (a1[11 ] + a1[29 ] - a1[24 ]) ^ 0x32 ) == 117 , (a1[2 ] ^ (a1[20 ] + a1[0 ] + a1[8 ] * a1[6 ] * a1[8 ] * a1[0 ] - a1[19 ]) ^ 0x62 ) == 83181080 , ((a1[14 ] * a1[32 ] + a1[29 ] + a1[22 ] - a1[18 ] - a1[1 ]) ^ 0x64 ) == 3243 , ((a1[18 ] - a1[4 ]) ^ (a1[16 ] + a1[7 ]) ^ (a1[14 ] + a1[18 ] - a1[7 ] - a1[14 ]) ^ 0x65 ) == -25 , ((a1[13 ] - a1[7 ]) ^ (a1[2 ] - a1[13 ]) ^ (a1[0 ] - a1[4 ] - a1[14 ] - a1[13 ] - a1[26 ]) ^ 0x65 ) == -363 , ((a1[1 ] + a1[10 ] + a1[7 ] * a1[14 ] * a1[7 ]) ^ (a1[17 ] + a1[5 ] * a1[8 ]) ^ 0x37 ) == 239501 , (a1[5 ] ^ (a1[15 ] * a1[24 ]) ^ 0x61 ) == 5026 )) s.add(And((a1[9 ] ^ (a1[28 ] * a1[0 ]) ^ (a1[29 ] + a1[12 ] + a1[16 ]) ^ 0x37 ) == 7058 , ((a1[6 ] * a1[8 ] + a1[6 ]) ^ (a1[18 ] - a1[7 ]) ^ 0x65 ) == 12399 , ((a1[12 ] + a1[8 ]) ^ (a1[1 ] - a1[1 ] * a1[32 ] * a1[30 ]) ^ 0x30 ) == -151548 , ((a1[4 ] + a1[32 ] * a1[18 ] + a1[22 ] - a1[12 ] - a1[22 ] - a1[12 ]) ^ 0x30 ) == 1624 , ((a1[9 ] * a1[3 ]) ^ (a1[26 ] + a1[13 ]) ^ a1[23 ] ^ 0x65 ) == 6569 , ((a1[17 ] - a1[3 ]) ^ (a1[14 ] * a1[26 ] * a1[11 ] * a1[25 ]) ^ 0x61 ) == -24990047 , ((a1[22 ] - a1[0 ]) ^ (a1[2 ] - a1[31 ] - a1[13 ] - a1[5 ] - a1[28 ]) ^ 0x65 ) == 372 , (a1[8 ] ^ (a1[4 ] * a1[14 ] + a1[20 ] + a1[19 ] + a1[25 ] + a1[21 ] * a1[8 ] - a1[1 ]) ^ 0x63 ) == 13326 , ((a1[8 ] + a1[29 ] - a1[25 ] - a1[32 ]) ^ (a1[24 ] * a1[4 ]) ^ 0x62 ) == 3910 , ((a1[2 ] * a1[15 ] + a1[27 ] - a1[30 ] * a1[29 ]) ^ 0x37 ) == 1316 )) s.add(And(((a1[5 ] - a1[2 ] * a1[24 ]) ^ (a1[21 ] - a1[20 ]) ^ a1[7 ] ^ 0x64 ) == 3290 , ((a1[9 ] * a1[15 ]) ^ (a1[7 ] - a1[14 ]) ^ a1[2 ] ^ 0x37 ) == -10137 , ((a1[5 ] * a1[6 ] + a1[26 ]) ^ (a1[11 ] + a1[3 ]) ^ 0x61 ) == 8601 , (a1[3 ] ^ (a1[8 ] + a1[16 ] + a1[27 ]) ^ (a1[28 ] + a1[31 ] * a1[12 ] + a1[21 ]) ^ 0x35 ) == 12752 , (a1[2 ] ^ (a1[6 ] - a1[20 ] - a1[8 ] * a1[9 ]) ^ (a1[16 ] + a1[6 ]) ^ 0x63 ) == -9964 , ((a1[1 ] * a1[2 ] * a1[32 ]) ^ (a1[29 ] + a1[27 ]) ^ (a1[1 ] * a1[18 ] * a1[8 ]) ^ 0x35 ) == 283359 )) for i in range (7 ): s.add(a1[i] == ord ('ESCAPE{' [i])) flg = "" if s.check()==sat: result = s.model() print (result) s.model().sorts() for i in range (33 ): flg += chr (eval (str (s.model().eval (a1[i])))) print (flg)
在s.add中间需要用And(xx,xxx)来进行2个条件联合约束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from z3 import * s = Solver() v1 = Real('v1' ) v2 = Real('v2' ) v3 = Real('v3' ) v4 = Real('v4' ) v5 = Real('v5' ) v6 = Real('v6' ) v7 = Real('v7' ) v8 = Real('v8' ) v9 = Real('v9' ) v11 = Real('v11' ) s.add(-85 * v9 + 58 * v8 + 97 * v6 + v7 + -45 * v5 + 84 * v4 + 95 * v2 - 20 * v1 + 12 * v3 == 12613 ) s.add( 30 * v11 + -70 * v9 + -122 * v6 + -81 * v7 + -66 * v5 + -115 * v4 + -41 * v3 + -86 * v1 - 15 * v2 - 30 * v8 == -54400 ) s.add(-103 * v11 + 120 * v8 + 108 * v7 + 48 * v4 + -89 * v3 + 78 * v1 - 41 * v2 + 31 * v5 - ( v6 * 64 ) - 120 * v9 == -10283 ) s.add(71 * v6 + (v7 * 128 ) + 99 * v5 + -111 * v3 + 85 * v1 + 79 * v2 - 30 * v4 - 119 * v8 + 48 * v9 - 16 * v11 == 22855 ) s.add(5 * v11 + 23 * v9 + 122 * v8 + -19 * v6 + 99 * v7 + -117 * v5 + -69 * v3 + 22 * v1 - 98 * v2 + 10 * v4 == -2944 ) s.add(-54 * v11 + -23 * v8 + -82 * v3 + -85 * v2 + 124 * v1 - 11 * v4 - 8 * v5 - 60 * v7 + 95 * v6 + 100 * v9 == -2222 ) s.add(-83 * v11 + -111 * v7 + -57 * v2 + 41 * v1 + 73 * v3 - 18 * v4 + 26 * v5 + 16 * v6 + 77 * v8 - 63 * v9 == -13258 ) s.add(81 * v11 + -48 * v9 + 66 * v8 + -104 * v6 + -121 * v7 + 95 * v5 + 85 * v4 + 60 * v3 + -85 * v2 + 80 * v1 == -1559 ) s.add(101 * v11 + -85 * v9 + 7 * v6 + 117 * v7 + -83 * v5 + -101 * v4 + 90 * v3 + -28 * v1 + 18 * v2 - v8 == 6308 ) s.add(99 * v11 + -28 * v9 + 5 * v8 + 93 * v6 + -18 * v7 + -127 * v5 + 6 * v4 + -9 * v3 + -93 * v1 + 58 * v2 == -1697 ) if s.check() == sat: result = s.model() print (result)
OLLVM(Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室于2010年6月份发起的一个项目,该项目旨在提供一套开源的针对LLVM的代码混淆工具,以增加对逆向工程的难度,只不过仅更新到llvm的4.0,2017年开始就没在更新。
分类
描述
指令替换(Instructions Substitution)(Sub)
将一条运算指令替换为多条等价的运算指令,例如:y=x+1变为y=x+1+1-1
虚假控制流(Bogus Control Flow)(bcf)
通过加入包含不透明谓词的条件跳转和不可达的基本块,来干扰IDA的控制流分析和F5反汇编
控制流平坦化(Control Flow Flattening)(Fla)
主要通过一个主分发器来控制程序基本块的执行流程,将所有基本代码放到控制流最底部,然后删除原理基本块之间跳转关系,添加次分发器来控制分发逻辑,然后过新的复杂分发逻辑还原原来程序块之间的逻辑关系
字符串加密
编写一个pass将其中的字符串信息使用一些加密算法进行加密,然后特定的时间进行还原
具体的例子看参考就行
参考:《安卓逆向这档事》十二、大佬帮我分析一下 - 『移动安全区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
1.简单ollvm可以通过交叉引用分析
参照:《安卓逆向这档事》十二、大佬帮我分析一下 - 『移动安全区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn
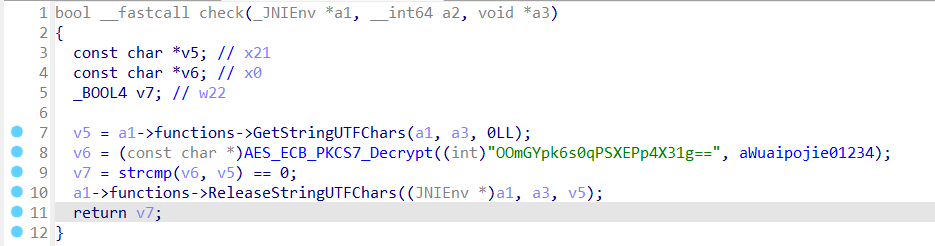
原始check函数
AES加密,然后和获取的数据比较
OLLVM混淆后的check函数
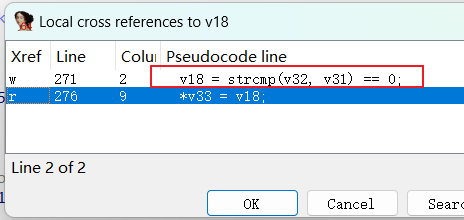
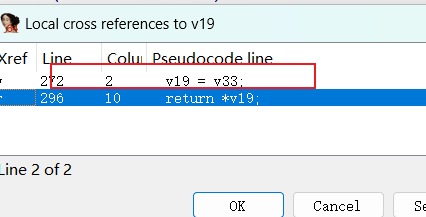
那么从返回值开始分析,交叉引用返回值,定位到v33
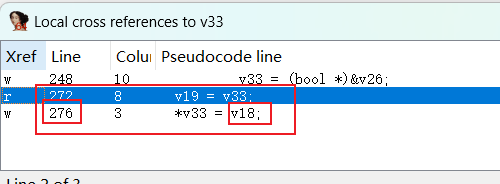
随后交叉引用v33
276行在272行下面,v33对应v19,那么v33指向内容被修改,v19指向内容也被修改,即v19指向内容的值为v18
交叉引用v18,和strcmp(v32,v31)有关
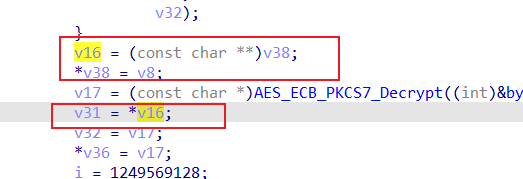
再交叉引用v32,可以看到v32为v17,v17为AES加密后的数据,对应未被OLLVM混淆的v6
再看看v31,对应v8
v8为获取的数据,对应未被OLLVM混淆的v5,最后即可分析完毕。
Instruction tracing 调试器将为每条指令保存所有修改后的寄存器值。
Basic block tracing 调试器将保存到达临时基本块断点的所有地址。
Function tracing 调试器将保存发生函数调用或函数返回的所有地址。
在解密的地方下断点,这里即为如下所示
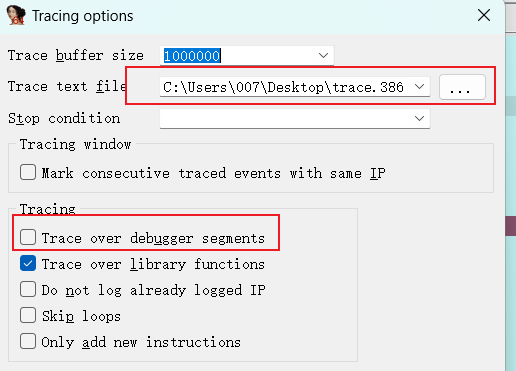
运行断下来之后,选择Debugger->Tracing->Tracing options,取消复选框Trace over debugger segments,然后选择Trace文件保存位置
然后Debugger->Tracing->Instruction tracing,三个跟踪选项作用在上面说过了
然后确定一个区域,即下两个断点
随后run就行,最终会在下一个断点停下来,然后路过的地方都会变为黄色
结束之后,就能在之前保存日志的地方看见具体信息
有时候Trace的时候没有变黄,那么说明没有运行到,就不需要再进行关注了
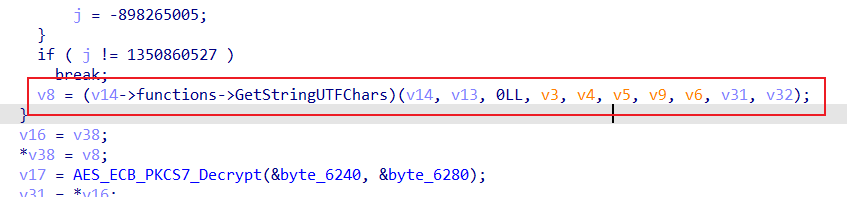
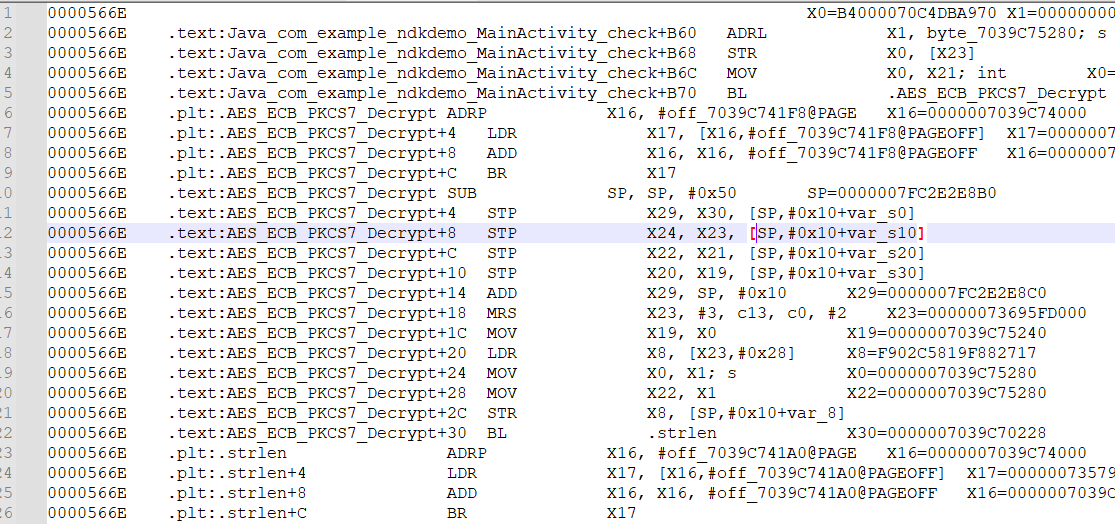
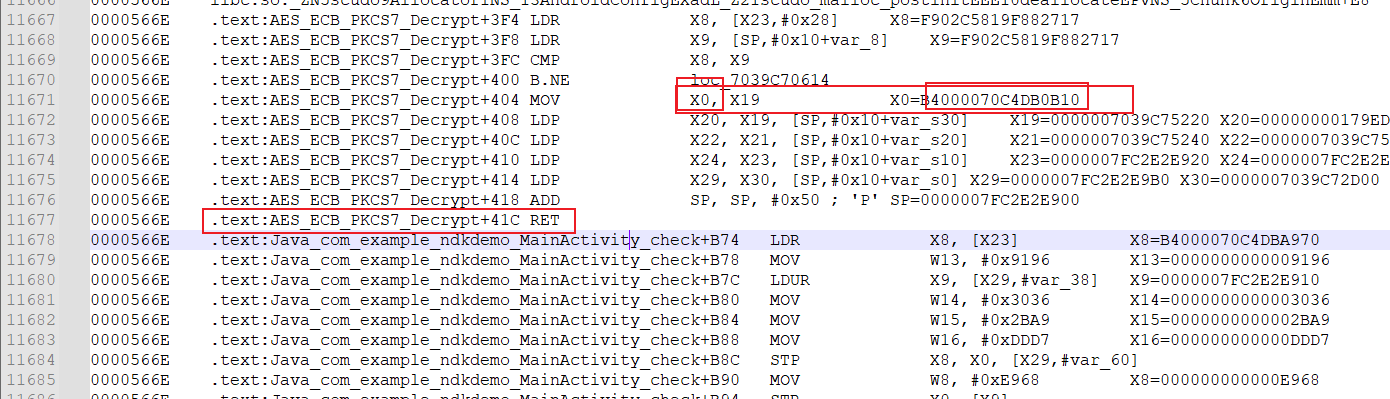
之后打开trace的日志分析,重点关注解密AES_ECB_PKCS7_Decrypt的返回结果,这里即X0为函数AES_ECB_PKCS7_Decrypt调用之后的返回结果,这个地址里面有个B4不知道是个啥
在IDA中跳转查看内存,得到最终的返回结果
Windows API 索引 - Win32 apps | Microsoft Docs
生成:generate-core-file生成core文件
调试:gdb programer core_file
https://www.52pojie.cn/thread-495115-1-1.html
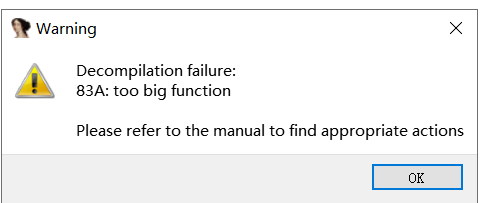
有时候当一个函数太长,就会导致IDA反编译失败,如下所示
这个可以通过设置IDA目录下的hexrays.cfg配置文件来设置最大反编译的代码长度,如下,将MAX_FUNCSIZE修改为1024即可
核心逻辑一般在bin\Data\Managed\Assembly-CSharp.dll,题目为[MRCTF2020]PixelShooter
可以用dnspy,在github上有Releases · dnSpy/dnSpy (github.com)
题目见:FlareOn1-Bob_Doge,可以调试的
如下所示
实际上应该是字符串
可以通过如下修改一下
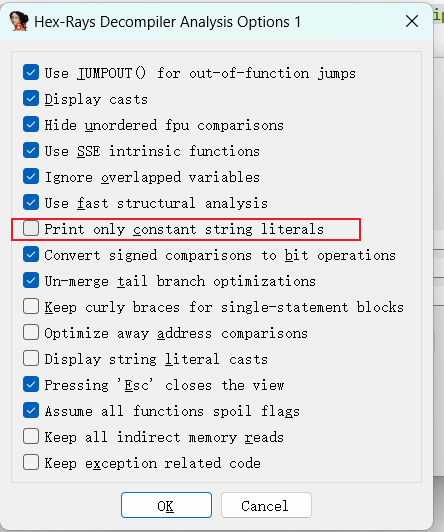
Edit->Plugins->Hex-rays ->options->Analysis options 1,去掉如下选项即可

.png)

.png)











 \
\