STATS_INC_ALLOCMISS(cachep); //不存在的话,则进入另一种分配--------其他缓冲池分配 objp = cache_alloc_refill(cachep, flags); /* * the 'ac' may be updated by cache_alloc_refill(), * and kmemleak_erase() requires its correct value. */ ac = cpu_cache_get(cachep);
out: /* * To avoid a false negative, if an object that is in one of the * per-CPU caches is leaked, we need to make sure kmemleak doesn't * treat the array pointers as a reference to the object. */ if (objp) kmemleak_erase(&ac->entry[ac->avail]); return objp; }
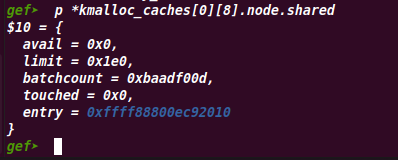
check_irq_off(); //获取node节点id和array_cache相关信息 node = numa_mem_id(); ac = cpu_cache_get(cachep); batchcount = ac->batchcount; //不知道干啥的 if (!ac->touched && batchcount > BATCHREFILL_LIMIT) { /* * If there was little recent activity on this cache, then * perform only a partial refill. Otherwise we could generate * refill bouncing. */ batchcount = BATCHREFILL_LIMIT; } //真实的node节点指针 n = get_node(cachep, node); BUG_ON(ac->avail > 0 || !n); //尝试从共享对象缓冲池shared_entry进行分配 shared = READ_ONCE(n->shared); if (!n->free_objects && (!shared || !shared->avail)) goto direct_grow; //相关自旋锁 spin_lock(&n->list_lock); shared = READ_ONCE(n->shared); /* See if we can refill from the shared array */ //transfer_objects()函数会从共享对象缓冲池shared_entry //转移batchcount个空闲对象到本地缓冲池进行分配 if (shared && transfer_objects(ac, shared, batchcount)) { //为什么设置touched? shared->touched = 1; goto alloc_done; }
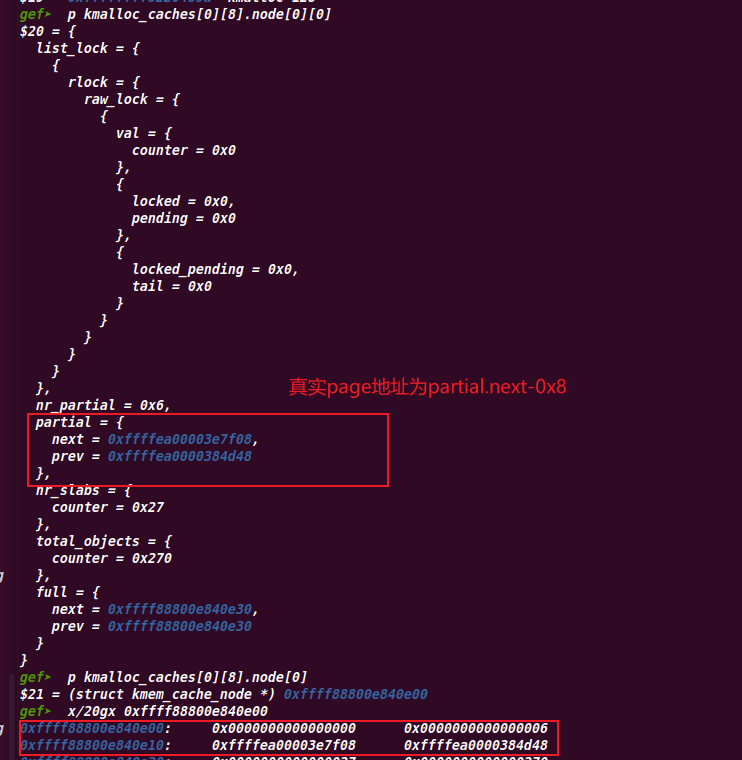
//共享对象缓冲池shared_entry没有空闲对象时,查看 //slabs_partial(部分空闲)链表和slabs_free(全部空闲)链表 while (batchcount > 0) { /* Get slab alloc is to come from. */ //进入实际分配函数 page = get_first_slab(n, false); //如果slabs_partial(部分空闲)链表和slabs_free(全部空闲)链表 //都没有则重新分配一个slab及对应空间 if (!page) goto must_grow;
direct_grow: if (unlikely(!ac->avail)) { /* Check if we can use obj in pfmemalloc slab */ if (sk_memalloc_socks()) { void *obj = cache_alloc_pfmemalloc(cachep, n, flags); if (obj) return obj; }
/* * cache_grow_begin() can reenable interrupts, * then ac could change. */ ac = cpu_cache_get(cachep); if (!ac->avail && page) alloc_block(cachep, ac, page, batchcount); cache_grow_end(cachep, page);
local_irq_save(flags); #ifdef CONFIG_PREEMPTION /* * We may have been preempted and rescheduled on a different * cpu before disabling interrupts. Need to reload cpu area * pointer. */ c = this_cpu_ptr(s->cpu_slab); #endif
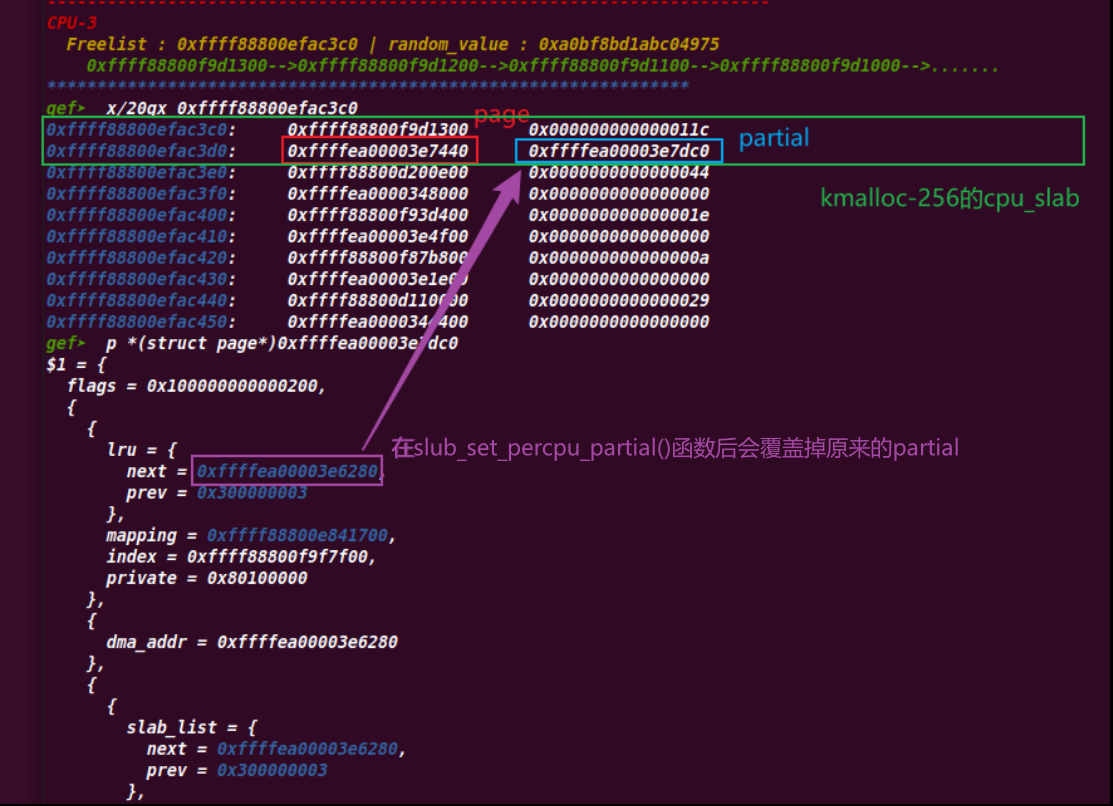
staticvoid *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsignedlong addr, struct kmem_cache_cpu *c) { void *freelist; structpage *page; //这个c即为对应kmalloc-xx下的cpu_slab //检查page是否为NULL,如果为NULL代表本地缓冲池的freelist已经分配完毕 //那么就会进入到new_slab page = c->page; if (!page) { /* * if the node is not online or has no normal memory, just * ignore the node constraint */ if (unlikely(node != NUMA_NO_NODE && !node_state(node, N_NORMAL_MEMORY))) node = NUMA_NO_NODE; goto new_slab; } redo: //这里有一些匹配检查,会检查page的nid和node是否能对上 //不能对上就不会进行相关分配,接着重来,不太懂 //也常常碰上不匹配的partial if (unlikely(!node_match(page, node))) { /* * same as above but node_match() being false already * implies node != NUMA_NO_NODE */ if (!node_state(node, N_NORMAL_MEMORY)) { node = NUMA_NO_NODE; goto redo; } else { stat(s, ALLOC_NODE_MISMATCH); deactivate_slab(s, page, c->freelist, c); goto new_slab; } }
//.....
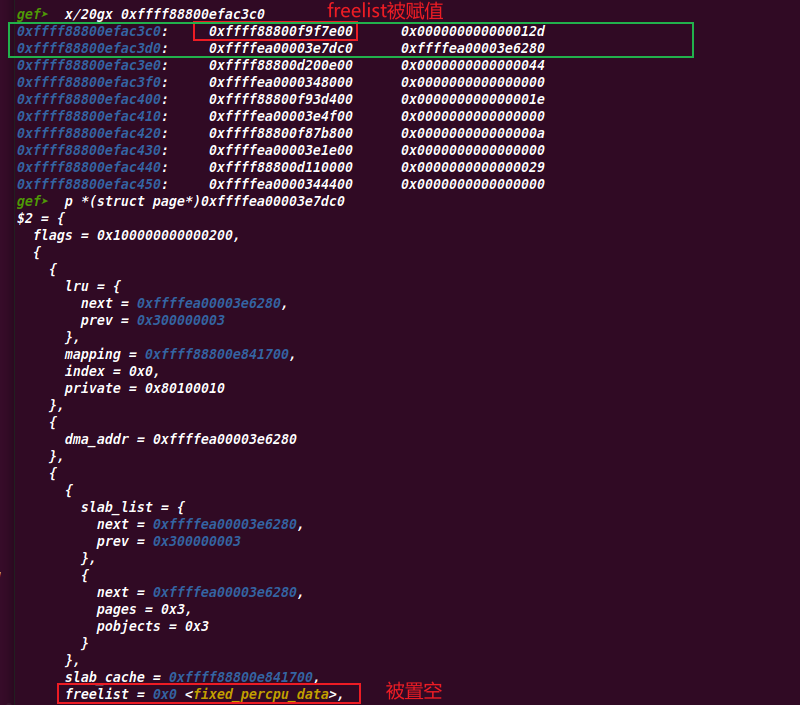
/* must check again c->freelist in case of cpu migration or IRQ */ freelist = c->freelist; if (freelist) goto load_freelist; freelist = get_freelist(s, page); if (!freelist) { c->page = NULL; stat(s, DEACTIVATE_BYPASS); goto new_slab; } stat(s, ALLOC_REFILL);
//本地CPU的page被赋值之后,加载freelist的过程 load_freelist: /* * freelist is pointing to the list of objects to be used. * page is pointing to the page from which the objects are obtained. * That page must be frozen for per cpu allocations to work. */ VM_BUG_ON(!c->page->frozen); c->freelist = get_freepointer(s, freelist); c->tid = next_tid(c->tid); return freelist;
//本kmalloc-xx对应的node中的partial不存在,从buddy伙伴系统分配 page = new_slab(s, flags, node); if (page) { c = raw_cpu_ptr(s->cpu_slab); if (c->page) flush_slab(s, c); /* * No other reference to the page yet so we can * muck around with it freely without cmpxchg */ freelist = page->freelist; page->freelist = NULL;