kernel笔记汇总
一、常见保护
1.KPTI
在v4.15之后会默认开启
内核页表隔离,开启之后可以访问用户空间内存,但是不能执行用户空间代码
即无法直接通过构造swapgs_iretq的ROP来返回用户态,可参考绕过
Linux Kernel KPTI保护绕过 - 安全客,安全资讯平台 (anquanke.com)
1 | cat /sys/devices/system/cpu/vulnerabilities/* |

这个也有类似的启动脚本
1 | -append "console=ttyS0 quiet root=/dev/sda rw init=/init oops=panic panic=1 panic_on_warn=1 kaslr pti=on" \ |
2.SMEP、SMAP、KASLR等
这个直接看启动脚本
(1)SMEP和SMAP
可以通过ROP修改CR3寄存器来绕过
(2)KASLR
通常需要泄露地址,可以通过以下命令查看当前基地址
1 | cat /proc/kallsyms | grep startup_64 |

但是也可以爆破,KASLR的随机化程度只有9bit,还是比较好爆破的,参考之后的爆破KASLR的模板
3.其他保护
(1)STACK PROTECTOR
类似用户态的cancary
(2)参考README.MD
有时候出题人给的README.MD会给配置
1 | CONFIG_SLAB=y |
如上就是使用SLAB分配,开启RANDOM和HARDENED保护,以及Hardened Usercopy(内核空间指针也会进行非常严格的安全性检查,包括不允许为空指针、不允许指向 kmalloc 分配的零长度区域、不允许指向内核代码段、如果指向 Slab 则不允许超过 Slab 分配器分配的长度、如果涉及到栈则不允许超出当前进程的栈空间等等。)和 Static Usermodehelper Path(modprobe_path 为只读,不可修改)
参考:【CTF.0x05】TCTF2021-FINAL 两道 kernel pwn 题解 - arttnba3’s blog
二、泄露地址
一般是开启KASLR的时候寻找地址
参照:信息泄漏 - CTF Wiki (ctf-wiki.org)
1.常用方法
Dmesg
显示启动时的一些信息,其中肯定包含很多函数地址
当设置如下即不能再用
- 启动时
echo 1 > /proc/sys/kernel/dmesg_restrict,即设置dmesg_restrict为1 - 编译内核时
CONFIG_SECURITY_DMESG_RESTRICT=y,这个效果等同
kallsyms
保存所有函数地址(全局的、静态的)和非栈数据变量地址
当其中的值如下时对应所示情况,一般题目启动时直接
echo 2 > /proc/sys/kernel/kptr_restrict
- 0:默认情况下,没有任何限制。
- 1:使用
%pK输出的内核指针地址将被替换为 0,除非用户具有CAP_ SYSLOG特权,并且group id和真正的 id 相等。(这个不太懂,root用户就可以看到) - 2:使用
%pK输出的内核指针都将被替换为 0 ,即与权限无关。(root用户也看不到,需要在启动时去掉这个才行)
module
这个是用来获取模块加载地址的
1 | cat /sys/module/module_name/sections/.text |
但是当编程时故意将模块隐藏起来的话,就不会被查看到了,下面有讲到。
三、下载generic版本内核
1 | apt search linux|grep linux-image |
肯定不太全,当然不同的apt源对应不同的,所以还是学会自己编译内核最好。
这种方法下载下来没有符号表,可以通过vmlinux-to-elf来获取符号表
四、打印地址
1.常规打印
1 | printf("0x%lx\n",leakAddr); |
有时候不加\n打不出来
1 | #define HEX(x) printf("[*]0x%016lx\n", (size_t)x) |
2.gdb式打印
1 | void gdbPrint(size_t* data,int len) |
实现效果
3.颜色打印
五、搜索内存
当不知道内存在哪里时,可以使用peda的搜索功能,搜索地址范围,常常在操控栈时很好用
1 | find "galf" 0xffffc900001d3f80 0xffffc900001d3f98 |

六、常见漏洞及利用
1.堆
前置知识
分配方式
通常而言为两种分配方式SLUB或者SLAB,SLUB默认会带上SLAB,但是可以进行设置,比如在编译内核的时候,使用CONFIG_SLUB=n, CONFIG_SLAB=y这样编译出来的内核就一定是SLAB分配的了。
分配基地址
kmalloc 从线性映射区分配内存,这块区域的线性地址到物理地址空间的映射是连续的,其起始地址为 page_offset_base,在不开启KASLR的情况如下:

kmalloc_caches
作为一个kmem_cache的结构体数组,管理着多个kmem_cache结构体指针。

但是不同版本下,由于分配方式的不同,导致也会kmalloc_caches的结构有点变化
比如在4.19.98的版本中,kmalloc_caches就只是一维数组

而在5.6的版本下,kmalloc_caches变成了二维数组

多出来的两个一维空间,就存放了kmalloc-rcl和dma-kmalloc,实际上也是相同的
SLUB下
通常我们分配的chunk的freelist为kmalloc_caches[xx].cpu_slab.freelist + CPUX_addr,也就是先得到对应CPU分配的基地址,然后加上cpu_slab.freelist 即为对应kmalloc-xx的freelist的实际地址,如下图可以看到

这里我在itExp中绑定了使用CPU3进行分配
1 |
|
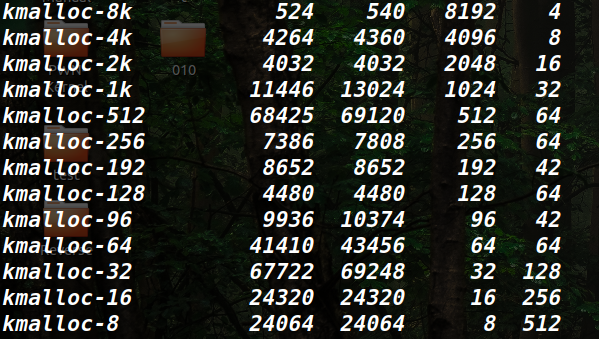
一维kmalloc_caches
kmalloc_caches[1]~kmalloc_caches[13]为kmalloc-8~`kmalloc-8k`
而在只有一维空间的kmalloc_caches中,即不存在kmalloc-rcl和dma-kmalloc的版本下,比如4.19.98
如下图可以看到,也是很顺利地放入CPU3对应的kmalloc-32的freelist中

但是CPU个数的不同,分配的基地址通常也会发生变化,这个具体还是看__per_cpu_offset这个全局变量中保存的内容吧,具体的细节不太知道

如图为4个CPU的情况,这个还是不太一样的。
多维kmalloc_caches
kmalloc_caches[0][1]~kmalloc_caches[0][13]为kmalloc-8~`kmalloc-8k`
kmalloc_caches[1][1]~kmalloc_caches[1][13]为kmalloc-rcl-8~`kmalloc-rcl-8k`
kmalloc_caches[2][1]~kmalloc_caches[2][13]为dma-kmalloc-8~`dma-kmalloc-8k`

内存管理如下

在二维空间的kmalloc_caches下,依据CPU的不同,有不同的freelist,比如在有4个CPU的情况下,我们将程序绑定在CPU3上,如上面提到的一样
qemu启动效果之后,输入top,效果如下

那么我们的itExp程序绑定的CPU3分配到的基地址即为0xffff88800f380000,结合kmalloc_caches中对应kmalloc-xxx下的cpu_slab.freelist

那么我们的kmalloc-32的freelist即为0xffff88800f380000+0x2d260,如下图可以看到,我们释放的chunk确实是放入了CPU3上对应的kmalloc-32的freelist中

当然,在SLUB分配下,由于FD指针的存在,freelist更像是一个单向链表,freelist中的第一个chunk作为链表头依据FD指针串联起整个freelist
仅SLAB下
同样也具备多维或者一维的kmalloc_caches
kmalloc_caches[0][1]~kmalloc_caches[0][2]为kmalloc-96~kmalloc-192
kmalloc_caches[0][3]~kmalloc_caches[0][4]不知道为什么没有
kmalloc_caches[0][5]~kmalloc_caches[0][22]为kmalloc-32~kmalloc-4M
同理对应的多维和一维也是类似的

分配方式上有点不同,具体的比较复杂,可以参考如下:
(41条消息) slab内存管理方案学习记录_liuhangtiant的博客-CSDN博客
这种情况下的Chunk其实不带FD指针的,所以只用于freelist上即可,简单来说,slab的freelist更像是一个数组进行索引。
- 首先找到索引,也就是
CPUX_addr + kmalloc_caches[xx][xx].cpu_cache.avail对应的值,以CPU3和kmalloc-1024为例:

- 然后再找到
freelist的地址,即CPUX_addr + kmalloc_caches[xx][xx].cpu_cache.entry

其实通过观察我们可以知道,entry其实也就是cpu_cache+0x10而已。那么现在我们得到freelist的地址,就将其当作一个数组进行取用,比如这里的索引idx为2,那么我们下一次分配就会取freelist[2]这个obj,但是这里很奇怪,这个索引是从1开始的,如下:
下一次分配取到chunk是0xffff88800d538400而非0xffff88800d538c00,我感觉这个索引idx更像是一个计数,表示还剩2个chunk可用,从尾部开始取用
🔺注:
当然以上的情况实际操作起来太麻烦,还不如写个小插件,自己进行计算
参考自己写的小工具:PIG-007/kernelAll (github.com)
SLAB:

SLUB:
这个带上了计算swab和random值得功能,也就是开启了harden的情况下,当然也还有FD偏移位置改变的情况,不过需要设置
修改cred结构体
这个就不用说太多,通常是0xa8大小的结构体,清空前28字节
1 | char credBuf[0xa8] = {0}; |
修改FD申请
(1)HARDENED保护
不过从4.14的内核版本开始,就存在freelist_ptr加密了,不过需要在编译内核的时候加入CONFIG_SLAB_FREELIST_HARDENED选项来启用,并且加密形式在不同版本不太一样。
1 | //v4.14 |
这里的ptr即当前释放的chunk地址,ptr_addr为指向下一个free_chunk的地址,所以中间相当于有一个random值不知道。这个值在linux/slub_def.h中被定义
1 |
|
并且在mm/slub.c中的kmem_cache_open函数中被赋值
1 | static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags) |
参考Slub Freelist Hardened (rtfingc.github.io)
这里需要我们获得random的值,这个值保存在对于size的kmem_cache中,该结构体定义在/linux/slub_def.h中如下
1 | //v4.17 |
并且不同size的kmem_cache对应的random不同。
在有DEBUG信息的内核中,我们尝试寻找0x10大小的kmem_cache比如我们寻找0x10大小的就需要在保存所有kmem_cache的全局变量结构kmalloc_caches中寻找,不过需要注意的是,好像很多时候不是按照顺序来排布的,如下图,我们就需要寻找kmalloc-16,但是这里它的索引为4,而不是2,不知道为什么。

另外kmalloc_caches[0]并不是一个kmem_cache结构的,而是一个其他类型,暂时不知道用来干啥。

那么回到正题,先寻找下random,这个就是0x10大小的kmem_cache中保存的random值了。

那么我们得到random值就可以算出下一个chunk在哪里了
但是通常意义上如果开启了这个保护,我们是得不到堆地址的,最多得到保护之后的fd的值,没办法算出来random的值,但是由于是异或了当前堆地址ptr和堆地址+size(ptr_addr),那么我们对size做文章,这样可以找出一些规律。
参考slub堆溢出的利用 - 安全客,安全资讯平台 (anquanke.com)
🔺注:
在该内核下的同一个size的kmem_cache的random值不管启动多少次都是固定的,无论有没有开启KASLR。(至少我在本地测的时候是如此的)
未开启KASLR

开启KASLR

可以看到都是一致的。
但是放到题目中就不太确定了,就是将题目在本地运行测出来的random值和题目在远程运行测出来的random值是不是也是一样的呢,之前的西湖的easy_kernel题中貌似是一样的,但是我并没有实际测试,因为还没碰到..下回换个机器测试下。或者说和qemu还是环境cpu都有关系吗,期待大佬回答。
而且在后面的新版的HARDENED中也有提到,加入swab运算之后,貌似会对random值再做一个低2个字节的处理,这个是怎么处理的呢,还是有点不太懂。
①0x8为例
0x10对齐的堆块其fd均一样,取其fd直接异或0x8即可得到kmalloc-8的random值

原因如下,0x10对齐的堆块异或其值+0x8并不会造成进位,所以异或得到的值都是一样的

②0x10,0x20,0x30等等
这种类型的其fd和random值一般差半个字节,大不了直接爆破,1/16的概率

并且观察可以发现,在0x10的情况下也会有重复的部分,同样的,该重复的部分异或0x10也会是random值

具体的还是自己摸索或者看一只狗师傅的:slub堆溢出的利用 - 安全客,安全资讯平台 (anquanke.com)
泄露random
以下泄露Random样例也是参照一只狗师傅的
1 | Add(0, 0x100); |
获得堆地址任意写
但是获得堆地址不太好整,需要找到freelist的最后一个堆块last_chunk,然后其fd异或random即可得到该堆块的地址,获得堆块地址后,直接释放该堆块last_chunk,然后通过之前一个堆块pre_chunk溢出或者UAF,按照异或规则修改last_chunk的fd,就能实现任意申请了。
以8192大小为例,申请到最后一个chunk时释放,然后再申请就能申请回来了。

注意获取堆地址的时候,由于不同size的kmem_cache的最大freelist数量差异较大,size越大的其freelist链表个数越少,越容易申请到最后一个。
(2)HARDENED新版改动
kasan_reset_tag
从v5.0开始,加了一个新的东西
1 | kasan_reset_tag((void *)ptr_addr)); |
这个不知道用来干啥的,有点蒙圈
1 | //linux/kasan.h |
swab
从v5.6.4开始,又加了一个运算
1 | swab(kasan_reset_tag((void *)ptr_addr))); |
本质上是大小端互换,比如
1 | int before = 0xaabbccdd; |
这个直接解,参照哪个师傅的来着,忘记了…..
1 |
然后又不知道从哪个版本开始,FD的存放位置发生改变,放在了chunk_addr+(size/2)的位置上,以0x80大小的chunk为例子(反正v5.0没有,v5.7有)

此外计算方式也有点变化,ptr_addr不再是当前chunk的地址,而是FD的地址,同时还是会与上面的运算做一个简单的合并:
1 | FD_addr == chunk_addr + size/2 |
所以当我们本地把random值测出来之后,再依据freelist的最后一个直接改next_addr然后套入上述公式,获得FD值,将FD值写入即可完成上述任意堆块申请。(但是远程还没有试过,想来依据最近的easy_kernel中测出来的情况应该是random值也是不变的)
同样的当位于freelist的最后一个chunk时,next_chunk_addr = 0,上述公式就变成如下
1 | FD_addr == chunk_addr + size/2 |
进而可以测出FD_addr,得到chunk的地址。当然,前提是建立在远程的random值不会发生改变。
如果远程的random值会发生改变的话,那么直接将当前FD_value异或需要劫持的fake_chunk_addr,那么一直将freelist申请完,之后再接着申请就能得到fake_chunk_addr。这种情况我们可以借助连续的两个FD_value中间4个字节是否发生改变来进行判断,如果改变了,那么代表freelist即将结束,这时候就可以进行修改了。不过修改之后,该size的kmem_cache的freelist链表就会损坏,要么重新修复,要么就申请其他size的kmem_cache。
但是还有一个问题就是,如果开了下面的RANDOM保护,那么我们测出来的random值其实就不一定准确了,因为freelist中的chunk地址不是连续的,我们用连续的地址来测势必导致测出来的random值的低2个字节不同,这时候就需要申请到freelist的最后一个chunk,取得其FD值的低2个字节和我们之前测出来的random一合并就是最终的random值了。不过这个怎么判断是freelist的最后一个chunk也有点问题…
double_free
在开启了HARDENED这种情况下,对于FD指针会添加一个检测
1 | //mm/slub.c |
检测double_free,其实就相当于是fastbin中的double_free检测,检测freelist中的第一个和即将放进入freelist中的chunk是否相等。

所以同理可得,也可以说如下,在中间加入一个chunk的free即可绕过
1 | free chunk1 |
但是在内核环境下,啥时候都可能碰到申请chunk,所以有时候可能再申请的时候不能成功申请到chunk1->chunk2->chunk1的顺序
这时候如果最好还是绑定到一个CPU上
1 | // 绑定到一个cpu上 |
(3)RANDOM保护
在v4.7及之后存在,编译内核时加入CONFIG_SLAB_FREELIST_RANDOM=y选项,会启用Fisher-Yates随机排列算法打乱freelist的顺序
这个情况下每次更新freelist的时候,会打乱freelist中空闲的chunk,造成无法简单申请到指定的chunk,不过我们可以修改FD之后,多次申请,也可以申请到修改之后的chunk。
也是参考Slub Freelist Hardened (rtfingc.github.io)
借助prctl函数寻找cred地址
🔺注:需要存在任意读
prctl函数的PR_SET_NAME功能可以设置task_struct结构体中的comm[TASK_COMM_LEN]成员。
1 | char target[16]; |
然后内存搜索定位
1 | //search target chr |
之后再借用任意写或者修改FD申请来修改cred结构中的内容即可。
借助stat设备修改函数指针
原理就是劫持seq_operations结构体的函数指针,进而控制程序流。
西湖论剑–easy_kernel
西湖论剑2021线上初赛easykernel题解 - 安全客,安全资讯平台 (anquanke.com)
有如下结构体,大小为0x20,当我们可以申请0x20大小的Chunk,然后释放,再打开/proc/self/stat设备就可以得到该结构体。
1 | struct seq_operations { |
如果存在UAF之类的就可以从里面读取函数偏移,获得kernel基地址,然后还可以修改里面的start函数指针,劫持使其指向我们的gadget,当我们对该设备进行读取操作时,就会调用该start指针,从而进入到我们劫持的gadget,进而可以程序控制执行流。使用如下汇编进行对该设备的操作。
1 | "xor rax, rax;" |
劫持之后再需要getshell就需要注意另一个结构体了
1 | struct pt_regs { |
当我们调用syscall的时候,会将以上寄存器压入内核栈中,然后形成如上的结构,即如下汇编所示
1 | __asm__( |
如上的汇编会在内核栈中形成如下

所以如果借助add_rsp xx;pop_ret这类指令,就可以将我们的控制流的栈拉高到我们可控数据范围,进而劫持栈。使用commit(cred)提权(这里的提权因为无法控制rdi,所以就借助init_cred来提权)。提权之后借助swapgs_restore_regs_and_return_to_usermode函数中的pop系列来调整栈,即借用了几个栈的位置,就得少几个pop,如图借用了5个栈数据,那么我们最后就得使得该函数少pop5个,即将swapgs_restore_regs_and_return_to_usermode函数的gadget+=9即可
1 | swapgs_restore_regs_and_return_to_usermode += 9; |
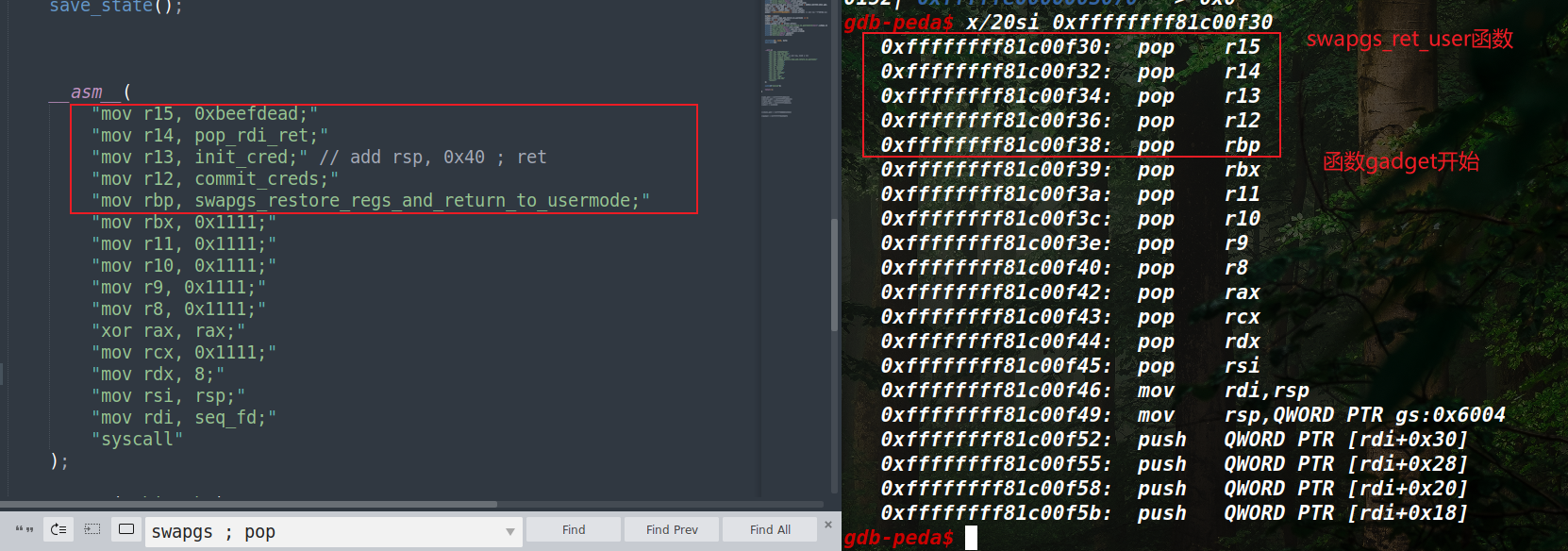
如上修改之后就可以当进入到该函数的swapgs的时候,将栈调整至最开始因为syscall而形成的保存pt_regs结构体中的用户态数据的地方,使得提权之后成功返回用户态
1 | struct pt_regs { |
所示栈如下

使用此种方法时一般可以先设置一些标志性数据,“AAAAAA”在栈上,然后搜寻即可,以此来寻找调栈所用的gadget。
1 | __asm__( |
然后在某个地址范围进行搜索,就能找到该结构体的位置,好像只能是peda比较好用
1 | find "AAAAAA" 0xffffc900001d3f80 0xffffc900001d3f98 |
借助ptmx设备(tty_struct)
1 | entry_SYSCALL_64`->`SyS_write`->`SYSC_write`->`vfs_write` |
原理就是劫持tty_struct结构体中的const struct tty_operations *ops结构体指针,然后再修改fake_tty_operations结构体中的pty_write函数指针,通过对该设备进行写操作进而调用劫持的函数指针,控制执行流程。
同时在调用的时候rax为从劫持的tty_struct结构体中获取的operations *ops指针,该指针可以被我们修改劫持。之后借助一个对rax和rsp进行操作的gadget--movRspRax_decEbx_ret进而劫持栈,完成程序流和栈的劫持。
1 | /* function to get root id */ |
2.栈
(1)commit_creds(prepare_kernel_cred(0));
这个算是比较常规的栈溢出,不过还需要注意SMEP/SMAP以及KPTI是否开启
①开启SMEP情况
这种情况一般直接溢出然后关闭,或者知道基地址之后可以尝试在内核完成提权然后返回用户态
ROP关闭SMEP保护,执行用户态提权代码
1 | /* function to get root id */ |
ROP在内核态提权后返回用户态起Shell
1 | void shell(void) { |
②未开启SMEP情况
直接调用用户空间的提权代码,返回之后起shell即可
1 | /* function to get root id */ |
(2)
3.mmap内存映射
还没看太懂,涉及文件系统和驱动的内存映射
可以参考LINECTF-2022-ecrypt,后面有提到借助kern_table数组来利用
4.常见提权手段
修改modprobe_path
这个设方法如果开启如下配置则不可用,表示modprobe_path为只读,不可修改
1 | //v4.11及之后存在 |
常常结合UAF漏洞来任意申请
starctf2019-hackme–starctf2019-hackme | PIG-007
西湖论剑–easy_kernel–2021 西湖论剑 线上初赛 WP – Crispr –热爱技术和生活 (crisprx.top)
1 | cat /proc/kallsyms| grep modprobe_path |
如果没有的话,可以先看借助kallsyms来__request_module函数的地址,然后查看该函数的汇编,获取modprobe_path的引用
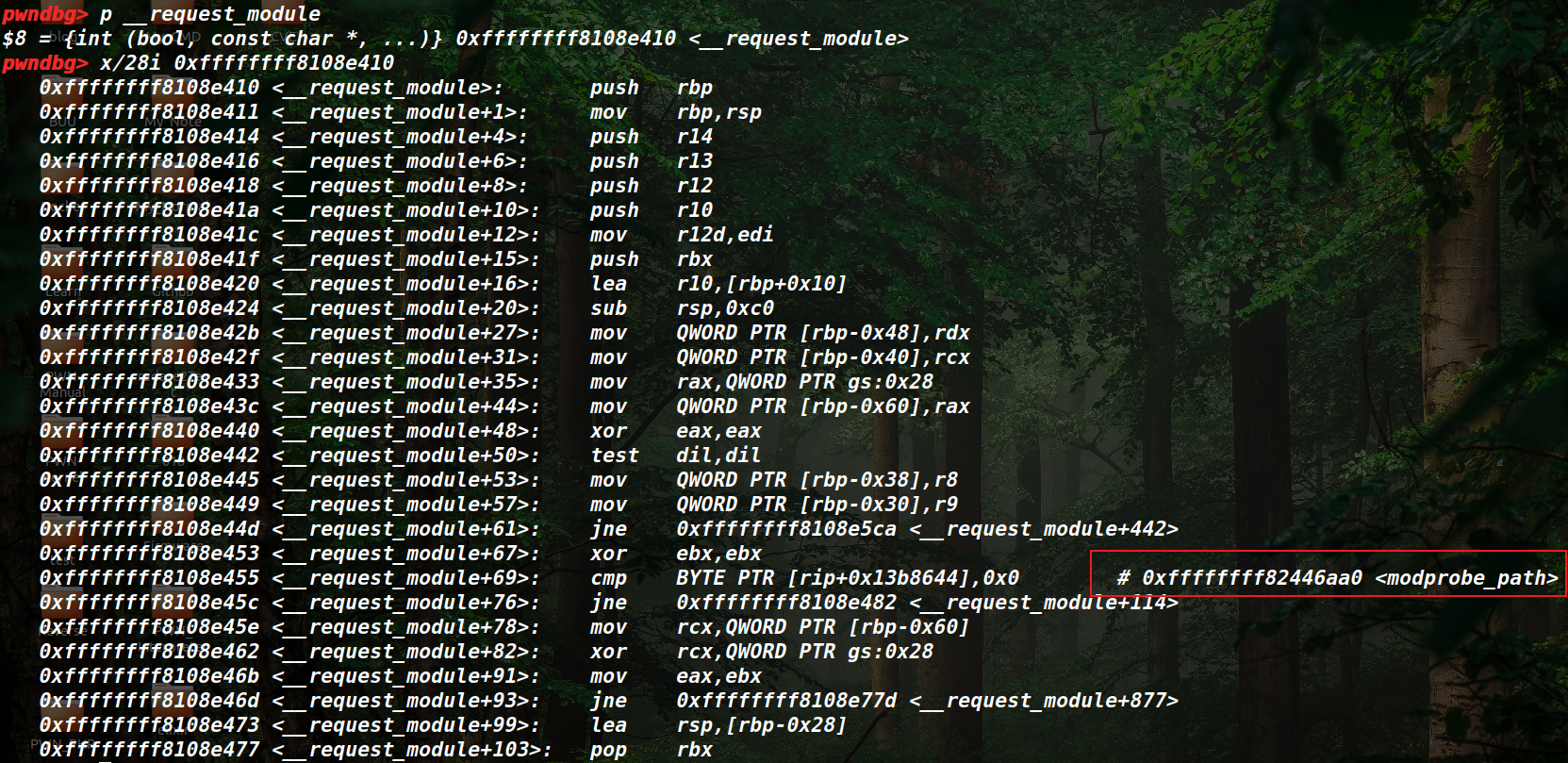
然后制作一个拷贝flag并且改权限的copy.sh文件,使得modprobe_path指向该文件,然后运行一个错误格式的文件,那么出错之后就会以root权限运行modprobe_path,从而以root权限运行我们的copy.sh,使得我们能够读取flag了。
1 | strncpy(mem,"/home/pwn/copy.sh\0",18); |
修改init_cred
init进程是初始进程,不被动态分配,知道kernel基地址的时候,就能得到该结构体的地址。
1 | cat /proc/kallsyms |grep init_cred |
这种方法一般用在没办法修改到本进程的cred结构体的时候,之后使用即可提权
1 | //pop_rdi_ret init_cred_addr commit_creds_addr即可 |
劫持prtcl_hook
1 | prctl->security_task_prctl->prctl_hook->orderly_poweroff->__orderly_poweroff->run_cmd(poweroff_cmd)-> call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC) |
(1)劫持为orderly_poweroff函数
劫持该hook为orderly_poweroff函数,然后调用prctl函数即可操纵程序流进入orderly_poweroff函数,再劫持poweroff_cmd即可顺着orderly_poweroff函数来运行call_usermodehelper(poweroff_cmd),该函数是以root权限运行,所以能够直接提权,不过一般运行一个反弹shell的程序。当然如果有KASLR就要爆破或者泄露了。
最后需要执行prctl(0,0);
(2)劫持为poweroff_work_fun函数
与劫持orderly_poweroff函数同理,劫持为poweroff_work_fun函数也可以以root权限执行poweroff_cmd
(3)获取地址
①prctl_hook
可以通过编写一个小程序,然后给security_task_prctl函数下断点,运行到call QWORD PTR[rbx+0x18]即可看到对应的rbx+0x18上存放的地址,即可获取到prct_hook_addr,劫持修改即可
②poweroff_cmd、orderly_poweroff、poweroff_work_fun
poweroff_cmd是一个全局变量,可以直接获取地址然后修改。可以直接使用nm命令来获取,或者直接进入gdb打印即可。

此外orderly_poweroff也是一样的获取。如果无法查到,那么可以启动qemu,先设置为root权限后
cat /proc/kallsyms | grep "orderly_poweroff"即可,或者编译一个对应版本的内核进行查询。

poweroff_work_fun函数也是类似的获取方式
七、意想不到的方式
1.QEMU逃逸
当没有关闭monitor时,可以直接ctrl+A C进去逃逸,解压rootfs.img读flag
1 | migrate "exec:cp rootfs.img /tmp " |
2.权限及相关配置问题
有的根目录或者bin目录的所有者不是root时
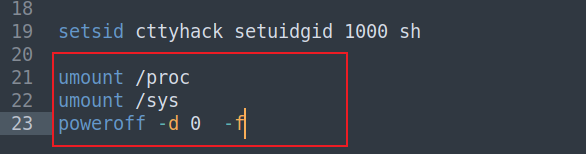
(1)bin目录不为ROOT

这样可以修改bin里面的命令,而init脚本在退出时,通常包含poweroff命令,或者umount命令,而init运行时是以root权限运行的,所以我们可以修改这些命令从而在输入exit命令调用init中在setsid剩下的命令时来直接cat flag或者获得shell
(2)根目录不为ROOT

那么在根目录下,虽然bin的所有者为root,但是缺可以对bin进行改名,然后我们伪造一个bin目录,里面放上我们伪造的命令,那么就可以以root权限调用这个伪造的命令了,如下为所示例子。
1 | mv bin evil_bin |
(3)密码未设置
如果root账号的密码没有设置的话,直接su即可登录到root,非预期的。
八、模板
1.保存状态
1 | void saveStatus() |
2.用户态起Shell
1 | void getRootShell(void) |
3.返回用户态
(1)没有KPTI
正常的swapgs和iretq
ROP布局如下
1 | swapgs_ret |
(2)存在KPTI
Linux Kernel KPTI保护绕过 - 安全客,安全资讯平台 (anquanke.com)
从swapgs_restore_regs_and_return_to_usermode函数某处开始执行
1 | mov rdi,rsp //该处开始执行 |
ROP布局如下
1 | swapgs_restore_regs_and_return_to_usermode+22, |
4.爆破KASLR
参考:【CTF.0x05】TCTF2021-FINAL 两道 kernel pwn 题解 - arttnba3’s blog
(1)POC里
1 | offset = (argv[1]) ? atoi(argv[1]) : 0; |
(2)打远程的EXP
1 | from pwn import * |
5.retUsr模板
1 | struct trap_frame{ |
九、常见可利用结构体
参考:【NOTES.0x08】Linux Kernel Pwn IV:通用结构体与技巧 - arttnba3’s blog
1.tty系列结构体—kmalloc-1024
打开设备:/dev/ptmx
tty_struct 的魔数为 0x5401,位于该结构体的开头,我们可以利用对该魔数的搜索以锁定该结构体。
上面堆->借助ptmx设备讲过了
2.seq_operations结构体—-kmalloc-32
打开设备:proc/self/stat
该结构体定义于 /include/linux/seq_file.h 当中,大小为0x20
1 | struct seq_operations { |
通过函数指针泄露地址,再劫持start函数指针后对该设备进行读写即可调用劫持的start函数指针,控制程序流程。读写的时候可通过syscall创建pt_regs结构体来布置内核栈环境,然后通过swapgs_restore_regs_and_return_to_usermode函数返回用户空间。
西湖论剑2021线上初赛easykernel题解 - 安全客,安全资讯平台 (anquanke.com)
3.subprocess_info结构体—kmalloc-128
通过以下语句可以分配得到一个subprocess_info结构体,不同版本大小不同,如下版本形式的为0x60,使用kmalloc-128分配器
1 | socket(22, AF_INET, 0); |
结构体
1 | struct subprocess_info { |
该结构体在分配时最终会调用其中的void (*cleanup)(struct subprocess_info *info);函数指针,所以如果存在一个UAF和条件竞争,在分配时启动另一个线程不断修改该函数指针,那么就能劫持程序流,再利用一些gadget就可以控制得到。
SCTF flying_kernel 出题总结 - 安全客,安全资讯平台 (anquanke.com)
4.ldt_struct结构体—kmalloc-16
(1)前置知识
结构体
ldt是即局部段描述符表(Local Descriptor Table),存放着进程的段描述符,在内核中有结构体ldt_struct与之对应。大小为0x10。
如下结构体
1 | //v5.17 /arch/x86/include/asm/mmu_context.h |
该结构体可以通过系统调用SYS_modify_ldt来操控,想要调用该系统调用号需要编译时开启如下设置,不过一般都是默认开启的,从v4.3版本才开始较为正式的一个编译设置
1 | CONFIG_MODIFY_LDT_SYSCALL=y |
系统调用函数
具体的函数调用如下
1 | //v5.17 /arch/x86/kernel/ldt.c |
也就是传入syscall相关参数,会调用不同函数,0对应read_ldt,1对应write_ldt(其实0x11的也差不多,就是oldmode设置为0了而已,具体的还得依据源码进行分析),依此看代码类似如下
1 | //read_ldt从ldt_struct->entries读取8字节给buf |
(2)实现任意读取
主要看write_ldt和read_ldt函数,由于调用write_ldt函数时,会创建一个新的ldt_struct一些和利用无关的代码就先省略了
1 | //v5.17 /arch/x86/kernel/ldt.c |
- 将我们的传入的数据指针
ptr,当作一个user_desc结构体拷贝给ldt_info - 然后依据
ldt_info来设置desc_struct结构体ldt - 之后依据
sizeof(ldt_struct)用kmalloc申请chunk作为new_ldt - 如果存在
old_ldt,那么就将old_ldt->entriesd的数据的拷贝给新的new_ldt->entries - 最后将
ldt(8个字节)的内容赋值给new_ldt->entries[ldt_info.entry_number] - 在退出前还会插入
new_ldt并且解开old_ldt,释放old_ldt
1 | //v5.17 /arch/x86/include/uapi/asm/ldt.h |
比如有个UAF漏洞,我们就可以借助该函数,申请0x10大小的堆块,修改其entries指针,再借助read_ldt函数进行读取
1 | static int read_ldt(void __user *ptr, unsigned long bytecount) |
- 即获取当前进程中的
ldt_struct结构体的entries指针指向的内存,拷贝bytecount个字节给用户
那么当如上述所示,借助UAF修改了entries指针之后,就可以进行任意地址读取最少可到达8192个字节的数据。
如果没有地址的话,可以使用爆破的方法来读取内核地址,因为如果没有命中内核空间copy_to_user会返回非0值,但是内核不会崩溃,借助这点特性可以用来爆破内核空间。
但是如果存在harden_usercopy和KASLR,最好还是借助page_offset_base和fork来从线性分配区中搜索数据,不然当copy_to_user的源地址为内核 .text 段(_stext, _etext)时或者线性分配区中的数据较为特殊时会引起kernel panic,致使内核崩溃。
原理就是在fork时最终调用到的是ldt_dup_context函数,该函数有如下操作
1 | memcpy(new_ldt->entries, old_mm->context.ldt->entries, |
会将父进程的拷贝给子进程,完全在内核中的操作,不会触发hardened usercopy的检查,那么只需要在父进程中设定好搜索的地址之后打开子进程来通过read_ldt()读取数据即可
1 | int pipe_fd[2]; |
(3)实现任意地址写
同样的还是关于entries指针,如下在write_ldt函数中的代码,entry_number可控,ldt不太可控,那么可以先write_ldt一个new_nr_entries出来,然后再下一次write_ldt就可以给old_nr_entries赋值,进而在memcpy的时候拷贝大量数据。
1 | old_nr_entries = old_ldt ? old_ldt->nr_entries : 0; |
而如果这时有个条件竞争,在拷贝过程中将new_ldt->entries给劫持了,那么就可以借助拷贝之后的语句new_ldt->entries[ldt_info.entry_number] = ldt;来依据ldt修改劫持之后的new_ldt->entries对应内存。
不过需要注意的是,虽然可以修改,但是其实ldt由于之前提到的设置原因,其数据会有所改变,不太能随意可控,但是如果可以设置4个字节的0数据,那就可以设置当前进程的euid了,这样也能提权,但是还没接触到怎么通过euid设置来提权。
但是arttnba3师傅写的用来修改euid之后调用seteuid的方法好使,不太清楚为什么,这个方法需要的数据不用太严苛吗?不太清楚哎。
【CTF.0x05】TCTF2021-FINAL 两道 kernel pwn 题解 - arttnba3’s blog
1 | desc.base_addr = 0; |
5.kern_table数组
前置知识
这个不能叫结构体吧,不过这个可以利用
1 | //v5.17 /kernel/sysctl.c |
其中包含很多/proc/sys/kernel/下的文件句柄,这些是在linux内核启动时就进行映射的,和文件相关一一对应,如果我们能修改这些句柄,比如将data指针修改到任意位置,当我们打开/proc/sys/kernel/下对应的文件时,就能依据data指针,读取到该指针对应的数据。
而我们主要就是利用其中的CONFIG_MODULES定义下的modprobe,也就是以前提权经常用到的modprobe_path,可以看到,modeprobe这个文件映射句柄其中保存着modprobe_path这个全局变量

内存分布如下

实现任意读取
内存映射
除了上述的启动内核时发生映射外,当我们运行程序时,也会在内核的线性分配区page_offset_base即0xffff888000000000发生映射,比如如下的v5.6版本下的内核,没开启KASLR的情况下映射偏移为0x2444100如下所示

可以看到数据完全一致,而由于是映射关系,当我们修改其中一部分的数据时,另一部分数据也会发生变化,尝试修改data指针为0xffffffff82446ab0,两边都发生了变化。

内存复制
除了内存映射区域之外,还有一个内存复制区域,也是在page_offset_base上,比如这里的偏移为0xec8a440

可以看到完全一样的,但是由于是复制的关系,所以不存在映射关系,所以我们可以将内存映射的modprobe的data指针指向内存复制的modprobe的data指针,打开/proc/sys/kernel/modprobe文件即可获取到内存复制区域的modprobe的data指针数据,即modprobe_path的地址,这样我们就可以在只有堆地址和任意写的时候,不泄露内核基地址的情况下,完成modprobe_path的地址泄露。
KASLR
如果开启了KASLR的话,就有点不同了,由于是文件内存映射和复制的关系,所以这个映射和复制的偏移量其实比较取决于文件系统和内核版本,内核的文件系统比较复杂,VFS接口下可连接一堆的文件系统,每个文件系统又都有点不一样,所以一般都需要实际分析,以下是我的测试结果
SVR4
这个文件系统也就是我们kernel题中常见的cpio后缀使用的,没有开启KASLR的时候,映射和复制的偏移都是确定的,实际调一下,借用peda插件的find功能可以容易搜索到。但是开启之后,复制的偏移基本不会变化,但是映射的偏移会发生变化,测试多次如下
1 | v5.6 |
但是观察也可以看到,其实偏移发生的话,相对于映射区域,只有一个字节发生改变,那么我们就可以尝试爆破这一个字节来获取。
ext4
这个文件系统的也比较常见,不过比较好的一点就是,实际测试结果发现映射和复制的偏移在开启KASLR之后都不会发生改变,所以测出来就可以直接使用了。
1 | v5.15.26 |
这个主要是最近的LINECTF上的encrypt这个内核题事后看WP出来的,忘记哪位师傅了。
其他猜想
之前的kern_table的结构可以看到,每个文件都有.mode属性,这个属性其实就是该文件的权限属性,也就是我们输入ls -al file出来的相关权限

我们也可以对其进行操控。
权限更改
猜想一下如果更改该文件,使其内容变为一个可执行的elf文件,功能为cat /flag,然后更改其权限,赋予suid的权限,那么在执行过程中,就可以以root权限来cat flag。形式如下

存在问题
但是这里有点问题,我实际操作的时候,权限倒是很容易更改,但是内容不能写入\x00和\n,就很不好制作一个可执行的ELF文件,不知道有没有什么其他办法绕过。
可参考:打造史上最小可执行ELF文件(45字节) - C 语言编程透视 (gitbook.io)
此外之前P神的文章也提到,如果只是suid的权限的话,用shell脚本是不行的,所以这方面也不太能够搞定。
谈一谈Linux与suid提权 | 离别歌 (leavesongs.com)
至今还是不知道有没有什么其他的方法来绕过。
6.__ksymtab数组
前置知识
通常用在开启FG-KASLR的情况,该保护需要编译时开启
1 | CONFIG_FG_KASLR=y |
通过nofgkaslr来关闭
不过我在编译设置.config的时候,没有找到这些选项,不知道为什么。
参考:
FGKASLR - CTF Wiki (ctf-wiki.org)
Kernel_pwn FG_KASLR in ROP | An9Ela (zhangyidong.top)
主要在于
内核符号表
__ksymtab.dataswapgs_restore_regs_and_return_to_usermodemodprobe_path存在于
.text_base到__x86_retpoline_r15的函数没有受到影响。显然commit_creds和prepare_kernel_cred()没有包含在内,但是可以在里面寻找一些gadget
以上均不会发生FG-KASLR的随机化
那么这里就是主要关注于__ksymtab数组,存在于该数组中的每一个函数块都有如下结构
1 | //v5.17 /include/linux/export.h |
注意是在v5.17下,在低版本下好像名字有点不同,不过也大同小异
绕过FG-KASLR
因为__ksymtab是不会被该机制影响的,所以我们肯定可以在没有开启KASLR的时候通过kallsym来获取到该地址,接着就可以找到对应函数的kernel_symbol结构体偏移,如下所示

所以就可以这样来得到对应的任意地址,计算的时候可以这样计算,通过补码来进行计算更快一点。

7.pipe管道—kmalloc-1024/kmalloc-192
参照:(31条消息) Linux系统调用:pipe()系统调用源码分析_rtoax的博客-CSDN博客_linux pipe 源码****
通常来讲,管道用来在父进程和子进程之间通信,因为fork出来的子进程会继承父进程的文件描述符副本。这里就使用当前进程来创建管道符,从管道的读取端(pipe_fd[0])和写入端(pipe_fd[1])来进行利用。
(1)使用方法
①创建
1 |
|
其中pipe2函数或者系统调用__NR_pipe2的flag支持除0之外的三种模式,可用在man手册中查看。
如果传入的flag为0,则和pipe函数是一样的,是阻塞的。
阻塞状态:即当没有数据在管道中时,如果还调用read从管道读取数据,那么就会使得程序处于阻塞状态,其他的也是类似的情况。
会默认创建两个fd文件描述符的,该fd文件描述符效果的相关结构如下
1 | //v5.9 /fs/pipe.c |
放入到pipe_fd中,如下
1 | int pipe_fd[2]; |
效果如下:

之后使用write/read来写入读取即可,注意写入端为fd[1],读取端为fd[0]
1 | char buf[0x8] = {0}; |
②释放
由于pipe管道创建后会对应创建文件描述符,所以释放两端对应的文件描述符即可释放管道pipe管道
1 | close(pipe_fd[0]); |
需要将两个文件描述符fd都给释放掉或者使用read将管道中所有数据都读取出来,才会进入free_pipe_info函数来释放在线性映射区域申请的相关内存资源,否则还是不会进入的。
(2)内存分配与释放
①分配
发生在调用pipe/pipe2函数,或者系统调用__NR_pipe/__NR_pipe2时,内核入口为
1 | SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags) |
函数调用链:
1 | do_pipe2()->__do_pipe_flags()->create_pipe_files()->get_pipe_inode()->alloc_pipe_info() |
调用之后会在内核的线性映射区域进行内存分配,也就是常见的内核堆管理的区域。分配点在如下函数中:
1 | //v5.9 /fs/pipe.c |
相关的pipe_inode_info结构如下
1 | //v5.9 /include/linux/pipe_fs_i.h |
②释放
直接使用close函数释放管道相关的文件描述符fd两端。
函数链调用链:
1 | pipe_release()->put_pipe_info()->free_pipe_info() |
需要注意的时,在put_pipe_info函数中
1 | //v5.9 /fs/pipe.c |
只有pipe_inode_info这个管理结构中的files成员为0,才会进行释放,也就是管道两端都关闭掉才行。
相关释放函数free_pipe_info
1 | //v5.9 /fs/pipe.c |
(3)利用
①信息泄露
pipe_buffer结构的buf
1 | //v5.9 /include/linux/pipe_fs_i.h |
其中的ops成员,即struct pipe_buf_operations结构的pipe->bufs[i]->ops,其中保存着全局的函数表,可通过这个来泄露内核基地址,相关结构如下所示
1 | //v5.9 /include/linux/pipe_fs_i.h |
②劫持程序流
当关闭了管道的两端时,调用到free_pipe_info函数,在清理pipe_buffer时进入如下判断:
1 | if (buf->ops) |
当管道中存在未被读取的数据时,即我们需要调用write向管道的写入端写入数据
1 | //v5.9 /fs/pipe.c |
然后不要将数据全部读取出来,如果全部读取出来的话,那么在read对应的pipe_read函数中就会如下情况
1 | //v5.9 /fs/pipe.c |
从而调用pipe_buf_release将buf->ops清空。
🔺注:(其实这里既然调用到了pipe_buf_release函数,那么我们直接通过read将管道pipe中的所有数据读取出来,其实也能执行该release函数指针的,从而劫持程序控制流的。)
那么接着上述的情况,那么在关闭两端时buf->ops这个函数表就会存在

而当buf->ops这个函数表存在时,关闭管道符两端进入上述判断之后,就会调用到其中的pipe_buf_release函数,该函数会调用到这个buf->ops函数表结构下对应的relase函数指针,该指针在上述的pipe_buf_operations结构中有提到

那么如果劫持了buf->ops这个函数表,就能控制到release函数指针,从而劫持控制流程。
不过pipe管道具体的保存的数据放在哪里,还是不太清楚,听bsauce说是在struct pipe_buffer结构下buf的page里面,但是没有找到,后续还需要继续看看,先mark一下。这样也可以看出来,每写入一条信息时,内核的kmalloc对应的堆内存基本是不发生变化的,与下面提到的sk_buff有点不同。
8.sk_buff—kmalloc-512及以上
参考:(31条消息) socketpair的用法和理解_雪过无痕_的博客-CSDN博客_socketpair
和该结构体相关的是一个socketpair系统调用这个也算是socket网络协议的一种,但是是在本地进程之间通信的,而非在网络之间的通信。说到底,这个其实和pipe非常像,也是一个进程间的通信手段。不过相关区分如下:
- 数据传输模式
pipe:单工,发送端fd[1]发送数据,接收端fd[0]接收数据socketpair:全双工,同一时刻两端均可发送和接收数据,无论信道中的数据是否被接收完毕。
- 模式
pipe:由flag来定义不同模式socketpair:默认阻塞状态
此外在《Linux系统编程手册》一书中提到,pipe()函数实际上被实现成了一个对socketpair的调用。
(1)使用方法
①创建
1 |
|
然后和pipe管道一样,使用write/read即可,不过这个的fd两端都可以写入读取,但是消息传递的时候一端写入消息,就需要从另一端才能把消息读取出来
1 | char buf[0x8] = {0}; |
②释放
1 | close(socket_fd[0]); |
可以看到和pipe是很相似的。
(2)内存分配与释放
在调用socketpair这个系统调用号时,并不会进行相关的内存分配,只有在使用write来写入消息,进行数据传输时才会分配。
①分配
在调用write进行数据写入时
函数链:
1 | write -> ksys_write() -> vfs_write() -> new_sync_write() -> call_write_iter() -> sock_write_iter() -> sock_sendmsg() -> sock_sendmsg_nosec() -> unix_stream_sendmsg()->内存申请/数据复制 |
在unix_stream_sendmsg开始分叉
1 | //v5.9 /net/unix/af_unix.c |
A.内存申请
先进行相关内存申请,即sock_alloc_send_pskb() -> alloc_skb_with_frags() -> alloc_skb() -> __alloc_skb()
还是挺长的,但是最重要的还是最后的__alloc_skb函数,
1 | //v5.9 /net/core/skbuff.c |
内存申请总结:
sk_buff为数据的管理结构从专门的缓存池skbuff_fclone_cache/skbuff_head_cache中申请内存,没办法进行控制skb->data为实际的数据结构size:0x140+n*0x40(0x40的倍数补齐)。即如果传入的数据长度为0x3f,则n为1,传入数据为0x41,则n为2。- 堆块申请:走
kmalloc进行申请,比较常见的种类,方便堆喷。
- 每调用
wirte函数写入一次数据,都会走一遍流程,申请新的sk_buff和skb->data,不同消息之间相互独立。
B.数据复制
相关内存申请完成之后,回到unix_stream_sendmsg函数,开始进行数据复制skb_copy_datagram_from_iter,即上述提到的。
1 | //v5.9 /net/core/datagram.c |
②释放
当从socker套接字中读取出某条信息的所有数据时,就会发生该条信息的相关内存的释放,即该条信息对应sk_buff和skb->data的释放。同样的,如果该条信息没有被读取完毕,则不会发生该信息相关内存的释放。
在read时进行的函数调用链:
1 | read -> ksys_read() -> vfs_read() -> new_sync_read() -> call_read_iter() -> sock_read_iter() -> sock_recvmsg() -> sock_recvmsg_nosec() -> unix_stream_recvmsg() -> unix_stream_read_generic() |
同样的在unix_stream_read_generic处开始分叉,也是分为两部分,下面截取重要部分
1 | //v5.9 /net/unix/af_unix.c |
A.数据复制
之后的函数调用链为
1 | unix_stream_read_actor() -> skb_copy_datagram_msg() -> skb_copy_datagram_iter() -> __skb_datagram_iter() |
最终进入__skb_datagram_iter,
1 | //v5.9 /net/core/datagram.c |
这里使用了感觉很复杂的机制,不是很懂。
B.内存释放
进入内存释放的函数调用链为
释放
skb->data部分:1
consume_skb()->__kfree_skb()->skb_release_all()->skb_release_all()->skb_release_data()->skb_free_head()
对应函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13//v5.9 /net/core/skbuff.c
static void skb_free_head(struct sk_buff *skb)
{
//其实head和data是一样的
unsigned char *head = skb->head;
if (skb->head_frag) {
if (skb_pp_recycle(skb, head))
return;
skb_free_frag(head);
} else {
kfree(head);
}
}可以看到使用的正常的
kfree函数释放
skb部分:1
consume_skb()->__kfree_skb()->kfree_skbmem()
相关函数如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33//v5.9 /net/core/skbuff.c
static void kfree_skbmem(struct sk_buff *skb)
{
struct sk_buff_fclones *fclones;
//克隆体相关的,没有fork之类的话一般不用太管的
switch (skb->fclone) {
case SKB_FCLONE_UNAVAILABLE:
//用专门的cache(skbuff_head_cache)进行回收
kmem_cache_free(skbuff_head_cache, skb);
return;
case SKB_FCLONE_ORIG:
fclones = container_of(skb, struct sk_buff_fclones, skb1);
/* We usually free the clone (TX completion) before original skb
* This test would have no chance to be true for the clone,
* while here, branch prediction will be good.
*/
if (refcount_read(&fclones->fclone_ref) == 1)
goto fastpath;
break;
default: /* SKB_FCLONE_CLONE */
fclones = container_of(skb, struct sk_buff_fclones, skb2);
break;
}
if (!refcount_dec_and_test(&fclones->fclone_ref))
return;
fastpath:
//用专门的cache(skbuff_fclone_cache)进行回收克隆的skb
kmem_cache_free(skbuff_fclone_cache, fclones);
}这个就不太好利用了。
同样的,当关闭的信道的两端,该信道内产生的所有的
sk_buff和skb->data都会得到释放
内存释放总结:
当从信道中将某条消息全部读取完之后,会发生该条消息对应的
sk_buff和skb->data的内存释放,且sk_buff释放到专门的缓存池中,skb->data使用正常的kfree释放当关闭信道两端,该信道内产生的所有的
sk_buff和skb->data都会得到释放,具体的调用链为:1
sock_close()->__sock_release()->unix_release()->__kfree_skb()
后面就类似了。
9.setxattr—近乎任意大小
这个总结过,直接扒过来
调用链为
1 | SYS_setxattr()->path_setxattr()->setxattr() |
代码如下
1 | //fs/xattr.c |
关注点在kvmalloc、copy_from_user、kvfree。
kvmalloc中的size可控,copy_from_user中的value可控
也就是说当freelist中存在我们需要修改的chunk,而该chunk又是我们控制的某个设备内存块时,(通过double-free或者UAF实现)那么我们就可以通过setxattr来对该设备内存进行任意写。虽然最后会释放,但是也只会影响内存块中存放下一个chunk地址处的内容0x8个字节,而当我们用不着这个地方的内容时,就不用太关注了。
🔺注:
使用的时候需要注意指定一个当前的exp程序,类似如下,第二个参数字符串任意。
1 | setxattr("/tmp/ufdExp", "PIG-007", &buf,0x100,0); |
10.msg_msg结构体—kmalloc-16至kmalloc-1024
这个在之前也总结过,不过总结得有些错误,也不太完善,这里再好好总结一下
参照:【NOTES.0x08】Linux Kernel Pwn IV:通用结构体与技巧 - arttnba3’s blog
Linux内核中利用msg_msg结构实现任意地址读写 - 安全客,安全资讯平台 (anquanke.com)
Linux的进程间通信 - 消息队列 · Poor Zorro’s Linux Book (gitbooks.io)
《Linux系统编程手册》
虽然写的是最大kmalloc-1024,但是在堆喷时,可以连续kmalloc(1024)从而获得连续的堆内存分布,这样都释放掉之后再经过回收机制就可以申请到更大的kmallo-xx了。
(1)使用方法
①创建
首先创建
queue_id管理标志,对应于内核空间的msg_queue管理结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//key要么使用ftok()算法生成,要么指定为IPC_PRIVATE
//代表着该消息队列在内核中唯一的标识符
//使用IPC_PRIVATE会生成全新的消息队列IPC对象
int32_t make_queue(key_t key, int msg_flag)
{
int32_t result;
if ((result = msgget(key, msg_flag)) == -1)
{
perror("msgget failure");
exit(-1);
}
return result;
}
int queue_id = make_queue(IPC_PRIVATE, 0666 | IPC_CREAT);使用简单封装的
msgget函数或者系统调用号__NR_msgget,之后保存数据的消息就会在这个queue_id管理标志,以及内核空间的msg_queue管理结构下进行创建
②数据传输
写入消息:
然后就可以依据
queue_id写入消息了,不同于pipe和socketpair,这个需要特定的封装函数(msgsnd/msgrcv)或者对应的系统调用(__NR_msgrcv/__NR_msgsnd)来实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22typedef struct
{
long mtype;
char mtext[1];
}msgp;
//msg_buf实际上为msgp,里面包含mtype,这个mtype在后面的堆块构造中很有用
void send_msg(int msg_queue_id, void *msg_buf, size_t msg_size, int msg_flag)
{
if (msgsnd(msg_queue_id, msg_buf, msg_size, msg_flag) == -1)
{
perror("msgsend failure");
exit(-1);
}
return;
}
char queue_send_buf[0x2000];
m_ts_size = 0x400-0x30;//任意指定
msg *message = (msg *)queue_send_buf;
message->mtype = 0;
send_msg(queue_id, message, m_ts_size, 0);读取消息:
之后即可依据
queue_id读取消息1
2
3
4
5
6
7
8
9
10
11
12
13void get_msg(int msg_queue_id, void *msg_buf, size_t msg_size, long msgtyp, int msg_flag)
{
if (msgrcv(msg_queue_id, msg_buf, msg_size, msgtyp, msg_flag) < 0)
{
perror("msgrcv");
exit(-1);
}
return;
}
char queue_recv_buf[0x2000];
m_ts_size = 0x400-0x30;//任意指定
get_msg(queue_id, queue_recv_buf, m_ts_size, 0, IPC_NOWAIT | MSG_COPY);mtype可通过设置该值来实现不同顺序的消息读取,在之后的堆块构造中很有用
- 在写入消息时,指定
mtype,后续接收消息时可以依据此mtype来进行非顺序接收 - 在读取消息时,指定
msgtyp,分为如下情况msgtyp大于0:那么在find_msg函数中,就会将遍历寻找消息队列里的第一条等于msgtyp的消息,然后进行后续操作。msgtyp等于0:即类似于顺序读取,find_msg函数会直接获取到消息队列首个消息。msgtyp小于0:会将等待的消息当成优先队列来处理,mtype的值越小,其优先级越高。
- 在写入消息时,指定
msg_flag
可以关注一下MSG_NOERROR标志位,比如说msg_flag没有设置MSG_NOERROR的时候,那么情况如下:
假定获取消息时输入的长度m_ts_size为0x200,且这个长度大于通过find_msg()函数获取到的消息长度0x200,则可以顺利读取,如果该长度小于获取到的消息长度0x200,则会出现如下错误

但是如果设置了MSG_NOERROR,那么即使传入接收消息的长度小于获取到的消息长度,仍然可以顺利获取,但是多余的消息会被截断,相关内存还是会被释放,这个在源代码中也有所体现。
1 | //v5.11 /ipc/msg.c do_msgrcv函数中 |
此外还有更多的msg_flag,就不一一举例了。
③释放
这个主要是用到msgctl封装函数或者__NR_msgctl系统调用,直接释放掉所有的消息结构,包括申请的msg_queue的结构
1 | //其中IPC_RMID这个cmd命令代表释放掉该消息队列的所有消息,各种内存结构体等 |
不过一般也用不到,可能某些合并obj的情况能用到?
此外还有更多的cmd命令,常用来设置内核空间的msg_queue结构上的相关数据,不过多介绍了。
总结
总结一下大致的使用方法如下
1 | typedef struct |
(2)内存分配与释放
①创建
A.内存申请
还是需要先创建
msg_queue结构体,使用msgget函数,调用链为1
msgget(key,msg_flag)->ksys_msgget()->ipcget()->ipcget_new()->newque()
主要还是关注最后的
newque()函数,在该函数中使用kvmalloc()申请堆块,大小为0x100,属于kmalloc-256,(不同版本大小貌似不同)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46//v5.11 /ipc/msg.c
static int newque(struct ipc_namespace *ns, struct ipc_params *params)
{
struct msg_queue *msq;
int retval;
key_t key = params->key;
int msgflg = params->flg;
//这个才是实际申请的堆块内存
msq = kvmalloc(sizeof(*msq), GFP_KERNEL);
if (unlikely(!msq))
return -ENOMEM;
msq->q_perm.mode = msgflg & S_IRWXUGO;
msq->q_perm.key = key;
msq->q_perm.security = NULL;
//进行相关注册
retval = security_msg_queue_alloc(&msq->q_perm);
if (retval) {
kvfree(msq);
return retval;
}
//初始化
msq->q_stime = msq->q_rtime = 0;
msq->q_ctime = ktime_get_real_seconds();
msq->q_cbytes = msq->q_qnum = 0;
msq->q_qbytes = ns->msg_ctlmnb;
msq->q_lspid = msq->q_lrpid = NULL;
INIT_LIST_HEAD(&msq->q_messages);
INIT_LIST_HEAD(&msq->q_receivers);
INIT_LIST_HEAD(&msq->q_senders);
//下面一堆看不懂在干啥
/* ipc_addid() locks msq upon success. */
retval = ipc_addid(&msg_ids(ns), &msq->q_perm, ns->msg_ctlmni);
if (retval < 0) {
ipc_rcu_putref(&msq->q_perm, msg_rcu_free);
return retval;
}
ipc_unlock_object(&msq->q_perm);
rcu_read_unlock();
return msq->q_perm.id;
}创建的结构体如下所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//v5.11 /ipc/msg.c
struct msg_queue {
//这些为一些相关信息
struct kern_ipc_perm q_perm;
time64_t q_stime; /* last msgsnd time */
time64_t q_rtime; /* last msgrcv time */
time64_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
struct pid *q_lspid; /* pid of last msgsnd */
struct pid *q_lrpid; /* last receive pid */
//存放msg_msg相关指针next、prev,比较重要,通常拿来溢出制造UAF
//和该消息队列里的所有消息组成双向循环链表
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;接着当使用
msgsnd函数传递消息时,会创建新的msg_msg结构体,消息过长的话就会创建更多的msg_msgseg来存储更多的消息。相关的函数调用链如下:1
msgsnd(msg_queue_id, msg_buf, msg_size, msg_flag)->do_msgsnd()->load_msg()->alloc_msg()
主要还是关注在
alloc_msg()函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46//v5.11 /ipc/msgutil.c
static struct msg_msg *alloc_msg(size_t len)
{
struct msg_msg *msg;
struct msg_msgseg **pseg;
size_t alen;
//最大发送DATALEN_MSG长度的消息
//#define DATALEN_MSG ((size_t)PAGE_SIZE-sizeof(struct msg_msg))
//这里的PAGE_SIZE为0x400,即最多kmalloc-
alen = min(len, DATALEN_MSG);
//使用正常
msg = kmalloc(sizeof(*msg) + alen, GFP_KERNEL_ACCOUNT);
if (msg == NULL)
return NULL;
//如果传入消息长度超过0x400-0x30,就再进行申请msg_msgseg。
//使用kmalloc申请,标志为GFP_KERNEL_ACCOUNT。
//最大也为0x400,也属于kmalloc-1024
//还有再长的消息,就再申请msg_msgseg
msg->next = NULL;
msg->security = NULL;
len -= alen;
pseg = &msg->next;
while (len > 0) {
struct msg_msgseg *seg;
//不知道干啥的
cond_resched();
alen = min(len, DATALEN_SEG);
seg = kmalloc(sizeof(*seg) + alen, GFP_KERNEL_ACCOUNT);
//申请完之后,将msg_msgseg放到msg->next这个单向链表上
if (seg == NULL)
goto out_err;
*pseg = seg;
seg->next = NULL;
pseg = &seg->next;
len -= alen;
}
return msg;
out_err:
free_msg(msg);
return NULL;
}msg_msg结构体如下,头部大小0x301
2
3
4
5
6
7
8
9//v5.11 /include/linux/msg.h
struct msg_msg {
struct list_head m_list;//与msg_queue或者其他的msg_msg组成双向循环链表
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;//单向链表,指向该条信息后面的msg_msgseg
void *security;
/* the actual message follows immediately */
};如下所示

msg_msgseq结构如下,只是一个struct msg_msgseg*指针1
2
3
4
5//v5.11 /ipc/msgutil.c
struct msg_msgseg {
struct msg_msgseg *next;
/* the next part of the message follows immediately */
};如下所示

相关内存结构:
在一个msg_queue队列下,消息长度为0x1000-0x30-0x8-0x8-0x8
一条消息:

两条消息:
以
msg_queue的struct list_head q_messages;域为链表头,和msg_msg结构的struct list_head m_list域串联所有的msg_msg形成双向循环链表
同理,同一个msg_queue消息队列下的多条消息也是类似的
内存申请总结:
- 使用
msgget()函数创建内核空间的消息队列结构msg_msgseg,返回值为消息队列的id标志queue_idmsg_msgseg管理整个消息队列,大小为0x100,kmalloc-256。- 其
struct list_head q_messages;域为链表头,和msg_msg结构的struct list_head m_list域串联所有的msg_msg形成双向循环链表
- 每次在该消息队列
queue_id下调用msgsnd()函数都会申请内核空间的msg_msg结构,消息长度大于0x400-0x30就会申请内核空间的msg_msgseg结构msg_msg为每条消息存放消息数据的结构,与msg_queue形成双向循环链表,与msg_msgseg形成单向链表大小最大为0x400,属于kmalloc-64至kmalloc-1024msg_msgseg也为每条消息存放消息数据的结构,挂在msg_msg单向链表中,大小最大为0x400,属于kmalloc-16至kmalloc-1024,当消息长度很长时就会申请很多的内核空间的msg_msgseg结构。
B.数据复制
调用完alloc_msg()函数后,回到load_msg()函数接着进行数据复制,函数还是挺简单的。
1 | struct msg_msg *load_msg(const void __user *src, size_t len) |
②释放
相关的函数调用链
1 | msgrcv(msg_queue_id, msg_buf, msg_size, msgtyp, msg_flag)->SYS_msgrcv()->ksys_msgrcv()->do_msgrcv()->do_msg_fill()->store_msg() |
首先关注一下do_msgrcv()函数,里面很多东西都比较重要
1 | static long do_msgrcv(int msqid, void __user *buf, size_t bufsz, long msgtyp, int msgflg, |
A.非堆块释放的数据读取
一般而言,我们使用msg_msg进行堆构造(比如溢出或者其他什么的)的时候,当需要从消息队列中读取消息而又不想释放该堆块时,会结合MSG_COPY这个msgflg标志位,防止在读取的时候发生堆块释放从而进行双向循环链表的unlink触发错误。
1 | //v5.11 do_msgrcv()函数中的 |
使用这个标志位还需要在内核编译的时候设置CONFIG_CHECKPOINT_RESTORE=y才行,否则还是会出错的
1 | //v5.11 /ipc/msgutil.c |
🔺注:还有一点不知道是不是什么bug,在某些内核版本中,至少我的v5.11中,MSG_NOERROR和MSG_COPY(后续会讲到)没有办法同时生效,关键点在于copy_msg()函数中,转化成汇编如下:
注意到红框的部分,获取rdi(msg)和rsi(copy)对应的m_ts进行比较,而copy的m_ts是从用户传进来的想要获取消息的长度,如果小于实际的msg的m_ts长度,那就标记错误然后退出。可以这个比较应该是在后面才会进行的,但是这里也突然冒出来,就很奇怪,导致这两个标志位没办法同时发挥作用。
B.释放堆块的消息读取
同理如果不指定MSG_COPY这个标志时,从消息队列中读取消息就会触发内存释放,这里就可以依据发送消息时设置的mtype和接收消息时设置的msgtpy来进行消息队列中各个位置的堆块的释放。
C.数据复制
不管什么标志位,只要不是MSG_NOERROR和MSG_COPY联合起来,并且申请读取消息长度size小于通过find_msg()函数获取到的实际消息的m_ts,那么最终都会走到do_msgrcv()函数的末尾,通过如下代码进行数据复制和堆块释放
1 | bufsz = msg_handler(buf, msg, bufsz); |
(3)利用
越界读取
这样,当我们通过之前提到的double-free/UAF,并且再使用setxattr来对msg_msgmsg中的m_ts进行修改,这样在我们调用msgrcv的时候就能越界从堆上读取内存了,就可能能够泄露到堆地址或者程序基地址。
使用setxattr的时候需要注意释放堆块时FD的位置,不同内核版本开启不同保护下FD的位置不太一样
为了获取到地址的成功性更大,我们就需要用到单个msg_queue和单个msg_msg的内存模型

可以看到单个msg_msg在msg_queue的管理下形成双向循环链表,所以如果我们通过msgget和msgsnd多申请一些相同大小的且只有一个msg_msg结构体的msg_queue,那么越界读取的时候,就可以读取到只有单个msg_msg的头部了
而单个msg_msg由于双向循环链表,其头部中又存在指向msg_queue的指针,那么这样就能泄露出msg_queue的堆地址了。
任意读取
完成上述泄露msg_queue的堆地址之后,就需要用到msg_msg的内存布局了
由于我们的msg_msg消息的内存布局如下

相关读取源码如下:
1 | //v4.9----ipc/msgutil.c |
所以如果我们可以修改next指针和m_ts,结合读取msg最终调用函数store_msg的源码,那么就能够实现任意读取。
那么接着上面的,我们得到msg_queue之后,可以再将msg_msg的next指针指回msg_queue,读出其中的msg_msg,就能获得当前可控堆块的堆地址。
这样完成之后,我们结合userfaultfd和setxattr频繁修改next指针就能基于当前堆地址来进行内存搜索了,从而能够完成地址泄露。
同时需要注意的是,判断链表是否结束的依据为next是否为null,所以我们任意读取的时候,最好找到一个地方的next指针处的值为null。
任意写
同样的,msg_msg由于next指针的存在,结合msgsnd也具备任意地址写的功能。我们可以在拷贝的时候利用userfaultfd停下来,然后更改next指针,使其指向我们需要的地方,比如init_cred结构体位置,从而直接修改进行提权。
十、常见函数总结
printk:
1 | printk(日志级别 "消息文本"); |
其中日志级别定义如下:
1 | #defineKERN_EMERG "<0>"/*紧急事件消息,系统崩溃之前提示,表示系统不可用*/ |
kmalloc:
1 | static inline void *kmalloc(size_t size, gfp_t flags) |
其中flags一般设置为GFP_KERNEL或者GFP_DMA,在堆题中一般就是
GFP_KERNEL模式,如下:
|– 进程上下文,可以睡眠 GFP_KERNEL
|– 进程上下文,不可以睡眠 GFP_ATOMIC
| |– 中断处理程序 GFP_ATOMIC
| |– 软中断 GFP_ATOMIC
| |– Tasklet GFP_ATOMIC
|– 用于DMA的内存,可以睡眠 GFP_DMA | GFP_KERNEL
|– 用于DMA的内存,不可以睡眠 GFP_DMA |GFP_ATOMIC
具体可以看
Linux内核空间内存申请函数kmalloc、kzalloc、vmalloc的区别【转】 - sky-heaven - 博客园 (cnblogs.com)
kzmalloc类似,就是分配空间并且内存初始化为0
kfree:
这个就不多说了,就是简单的释放。
copy_from_user:
1 | copy_from_user(void *to, const void __user *from, unsigned long n) |
copy_to_user:
1 | copy_to_user(void __user *to, const void *from, unsigned long n) |
这两个就不讲了,顾名思义。
十一、其他知识
1.内核模块隐藏
不知道为啥,这里不成功,显示
Unknown symbol module_mutex (err 0)
参考:简易 Linux Rootkit 编写入门指北(一):模块隐藏与进程提权 - 安全客,安全资讯平台 (anquanke.com)
2.文件系统
(1)SRV4文件系统
也就是常见的cpio后缀的

这个直接常用解包打包即可
(2)ext4文件系统
linux下挂载修改即可
1 | sudo mount rootfs.ext4 mountpoint/ |
常见的init启动脚本在/etc/init.d/rcS中
3.设备操作
- 获取设备信息
通过命令udevadm info -a -n /dev/tty获取相关设备信息
- 修改设备权限
当我们无法对设备进行操作时,可能是被设置了权限,可以通过/etc/udev/rules.d/下查看设置的一些规则

查看相关的内容,即指定相关设备后可以设置其类似用户组GROUP或者权限MODE等内容

- 读取
直接cat /dev/DEV_NAME相当于open_read_close这个设备
4.获取内核符号
当我们拿到一个bzImage或者无符号的vmlinux文件时,想要获取符号一般只有以下两种
(1)启动内核
我们利用busybox制作文件系统,然后使用qemu加载启动内核,启动之后在/proc/kallsyms保存所有地址,直接cat查看即可。
(2)使用工具
有个工具vmlinux-to-elf,这个还是很好使的,可以直接获得带符号的vmlinux文件
5.互斥锁和信号量
(1)互斥锁
用于线程互斥,一个互斥锁的加锁和解锁必须由同一个线程执行,是为了防止对一块内存的同时读写等问题。
1 |
|
(2)信号量
用于线程同步,合理使用公共资源。比如一个资源只有5份,每当一个线程获取该资源时,信号量就减一,当5个线程都获得该资源时,信号量减为0,其他线程就不能再获取该资源,处于等待状态,防止死锁。
1 |
|
6.系统调用使用
(1)传参约定
- 32位:EBX、ECX、EDX、ESI、EDI、EBP
- 64位:RDI、RSI、RDX、R10、R8、R9