ARM基础
一、前置环境:
先说明一下aarch64就是arm指令架构的64位版本,有相同,也有不同的地方。而Thumb指令集基本就相当于16位版本arm指令架构。
1.安装交叉编译环境:
1 | #注释头 |
然后就正常编译即可
1 | #注释头 |
2.安装运行环境:
1 | #注释头 |
这样对于静态的arm架构文件可以用qemu直接运行了,当然需要qemu对应支持。
3.调试文件:
(1)qemu运行起来
1 | #注释头 |
这里-g代表端口映射的意思,用来配合外面的gdb,这里用到端口12345。
-L代表加载运行库,这里安装运行环境之后基本都在这个位置/usr/…../。
(2)gdb远程附加调试:
1 | #注释头 |
这里不设置set architecture arm set architecture aarch64也行的。
之后就正常调试,不过中途断下来需要在qemu运行的终端地方ctrl+c,而不是gdb处。
二、基础学习:
1.寄存器:
ARM中:(32位版本)
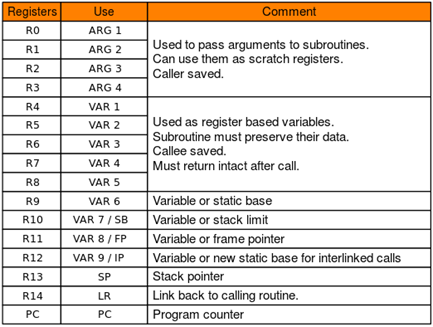
AARCH64中:(64位版本)

(1)R0R3:函数调用参数,代表第04个参数,剩下的参数从右向左依次入栈,函数返回值保存在R0中。(对应在aarch64中为R0R7,但是gdb调试或者IDA中一般显示X0X30,同时还有低32位的W0~W30)
(2)SP:类似rsp,esp,栈指针
(3)FP:类似ebp,栈指针
(4)LR:当发生函数调用时,会保存调用函数处的地址,退出函数时赋值给PC。
(5)PC:类似eip,rip,存储下一条指令的地址。
2.基础指令:
(1)STM以及LDM是指令前缀,表示多寄存器寻址,来装载和存储多个字的数据到内存,后面加上不同的后缀代表不同的指令,类似的有STMFA,STMIB, LDMFA,LDMDA等等:
常见的有FD,代表满栈转存,ED代表空栈转存。
▲满栈和空栈:满栈操作时SP指向上次写的最后一个数据单元,而空栈的栈指针SP指向第一个空闲单元。
类似有STMFD SP! { }和LDMFD SP! { }:
即相当于push和pop,在gdb中显示push,pop,IDA中显示STMFD和LDMFD。
STMFD SP!, {R11,LR}:将R11和LR入栈,相当于push R11以及LR中保存的值入栈。
同理LDMFD即相当于pop。
(2).STR指令:将前操作数寄存器数据复制到后操作数地址对应的内存上,类似mov
STR r3, [fp, #-0xc]:将寄存器r3中的值赋给fp-0xc地址对应的内存。这里fp就是R11。
STR r3, place:这里是赋值给pc+place地址对应内存。
等等….
(数据复制方向:前->后)
(3).LDR指令:也是指令前缀,后面也会跟上一些不同的后缀,常见有LDRB,LDRH等等。
LDR R0,[R1,#8]:将r1+8地址对应内存复制给r0。
(数据复制方向:后->前)
(4).B:跳转指令,同样也是类似一个前缀指令
① B:直接跳转,目标地址是相对于当前PC值的偏移地址
② BL:跳转之前会把PC值存到R14(LR)寄存器中,通常用于函数调用,从被调用函数返回时,通常需要用到BX LR;或者MOV PC,LR;等
③BX:跳转到ARM指令或者Thumb指令
④BLX:结合了BL和BX两个指令的功能。
三、ARM(32位架构)函数分类:
1.叶子函数:不做任何其他函数调用的函数
调用时的栈状态分析:和正常的x86差不多,压入fp,sub sp开辟栈空间。最后通过Add sp,fp,#0和pop{fp}再加上BX LR来返回。
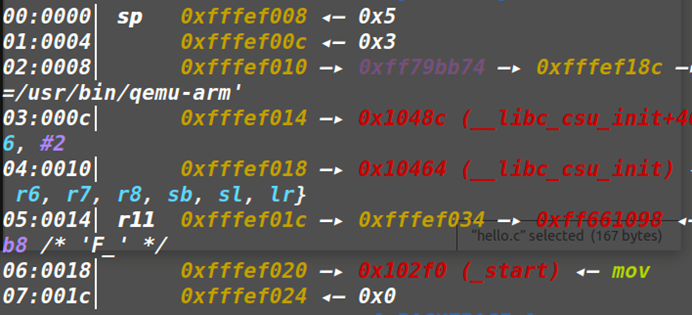
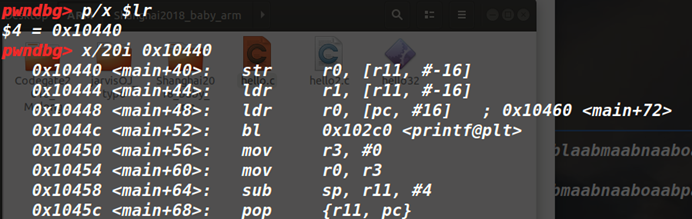
FP中的内容是上一个函数栈的FP指针,并且栈上不存在存放返回地址的地方,无法直接劫持返回地址。
▲栈模型如下:
1 | #注释头 |
但是这样就不好利用,那么就尝试劫持栈迁移一段距离,使得上一个非叶子函数的剩下的汇编代码所用到的栈上数据是我们伪造的栈中的数据,这样就能完成劫持上一个非叶子函数的返回地址。需要对汇编有一定功力。
2.非叶子函数:多了一点不同,即会压入FP时,将LR也压入,且LR先于FP压入,即函数栈中的FP指向的是保存的LR,而不是叶子函数中指向的是上一个函数栈的FP。最后通过sub sp,fp,#4加上pop {fp,pc}来返回。
▲其实返回时add和sub没多大差别,只针对后两个操作数的,也就立即数的符号相反呗,后两个操作数计算完成后赋值给sp实现栈还原。
▲栈模型如下:
1 | #注释头 |
虽然FP中的内容实际上是LR的内容,但其实也差不多,反正最后返回时都会发生SP移动,先取FP,再取对应的PC,所以实际怎么样也无所谓了:
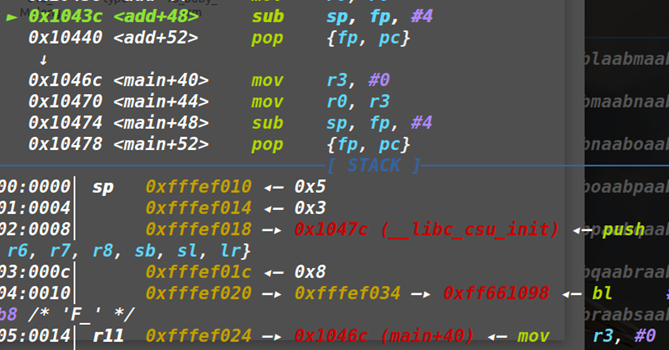
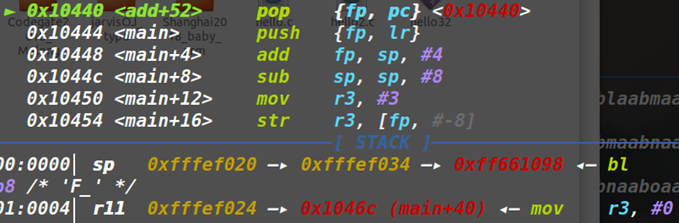
这样就相当于常规的32位栈模型ebp-eip了,只不过不涉及参数,一般需要用gadget来为对应参数赋值。
在常规栈溢出时,这里发挥重要作用的就是gadgets_addr了,一般可以先ROPgadget –binary ./pwn –only “pop”,查找对应的pop gadget。例如这里可以有pop {r0, r4, pc},那么完成利用的栈模型就如下:
1 | #注释头 |
将binsh_addr赋值给r0,junk_data赋值给r4,system_addr赋值给pc,完成利用。
★在栈溢出探索padding时,可以用pwndbg中的cyclic 200自动生成200个字符,然后输入,那么在arm(32位)架构下的非叶子函数中,一定会给pc赋值为我们的某个padding,这时候程序断下来,可以查看pc的值,用cyclic -l [PC值]来查找溢出点。


▲所以这里如果针对非叶子函数劫持了FP和FP+4,那么就相当于劫持栈并且控制程序流了,如果想调用函数还需要设置参数寄存器r0-r3才行。
简单的可以直接查找pop r0,pc之类的:ROPgadget –binary ./pwn –only “pop”,这种方式一般只能调用一个参数的函数。
泄露地址之类的一般还是需要用到ret2csu,arm(32位)下的ret2csu一般是用到:
1 | #注释头 |
即通过①来为R4-R10赋值,以及控制PC跳转到②,再利用R5地址对应的值来赋值给R3对应跳转,期间也可通过R7-R8来控制R0-R2的参数。这里需要满足R5处保存的是got表地址,即将R5赋值为func_got_addr即可。
四、aarch64架构的函数分类:其实就是ARM的64位版本,除了寄存器方面变化挺大,其他的调用方式什么的也差不了太多。
1.叶子函数:不做任何其他函数调用的函数
调用时的栈状态分析:和正常的arm差不多,FP入栈,sub sp开辟栈空间。最后通过Add sp,sp,#20和ret来返回。Ret相当于mov PC,LR。将LR中保存的地址给PC来执行。

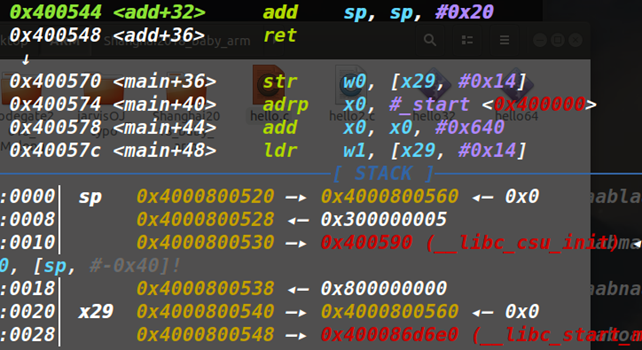
也同样通过栈劫持来控制。
2.非叶子函数:也差不多,但有些不同的是,进入函数后,会先开辟栈空间,先压入LR然后压入FP。stp x29, x30, [sp, #-0x30]!即非叶子函数栈中的FP和LR都保存在栈顶,最后通过LDP X29, X30, [SP+0x30+var_30]加上RET来返回。


可以看到进入非叶子函数中之后,先开辟栈空间,然后压入LR,再压入FP,栈模型如下:
1 | #注释头 |
paddint以下的部分才是我们要劫持的。
所以我们在该函数中的栈溢出劫持的其实不是该函数的返回地址,而是上一个函数的返回,所以这里同时也需要确保上一个函数中汇编代码剩下的操作不会对我们覆盖的栈上的值进行重要改写,不然栈上的数据就容易被破坏。
其次需要注意的是aarch64下的gadget搜索,用到:
ROPgadget –binary ./pwn –only “ldp|ret”
其实是一样的,ldp就类似pop,反正gadget运用算是更加灵活了。
▲通常也可以用ret2csu来搞定:
1 | #注释头 |
▲例如该SP即为0x40007ffe40:
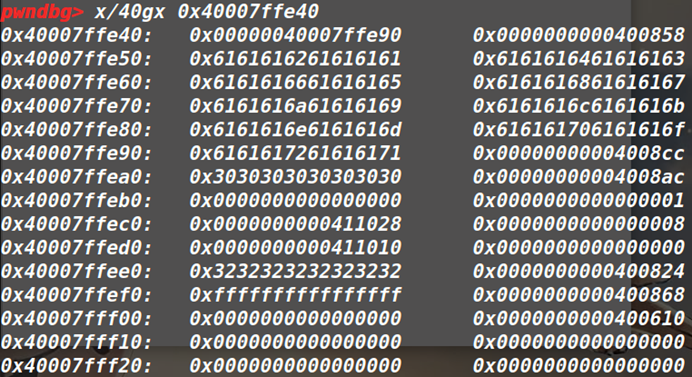
一直到0x40007ffe90为FP,那么如下
1 | #注释头 |
跳转0x4008CC(u_gadget1)之后,SP为0x40007ffea0依次赋值:

再通过LDP X29, X30, [SP+var_s0],#0x40和ret跳转到0x4008ac(u_gadget2)最终实现X0~X3赋值:

最终跳转函数真实地址0x400090f9c8,即需要给X21赋值为read_got_addr,参数依次为read(0,0x411010,0x8)。同时需要注意的是,在read完成之后,还是会回到当前的万能gadget处0x4008C4,再接着运行下去。然后一路运行下去,经过万能gadget中的RET返回到之前设置的0x40007ffee8处也就是0x400824,这个也是在最开始就设置好的,通常可以用来返回到read函数或者main函数处再执行栈溢出,之后就正常操控程序。
▲脚本示例:
1 | def aarch64_csu(call, x0, x1, x2,ret_addr): |
这个是没有栈劫持的。Aarch64的csu也不怎么用到,因为aarch64的csu赋值不是pop,SP基本不会动,而且大多时候都是SP寻址。
参考资料: