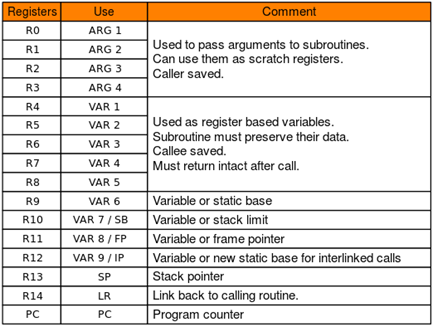
堆前置知识总结
一、main_arena总概
1.arena:
堆内存本身
(1)主线程的main_arena:
由sbrk函数创建。
最开始调用sbrk函数创建大小为(128 KB + chunk_size) align 4KB 的空间作为 heap
当t不够用时,用sbrk或者mmap增加heap大小。
(2)其它线程的per thread arena:
由mmap创建。
最开始调用 mmap 映射一块大小为HEAP_MAX_SIZE(32 位系统上默认为 1MB,64 位系统上默认为 64MB)的空间作为 sub-heap。
当不够用时,会调用 mmap 映射一块新的 sub-heap,也就是增加 top chunk 的大小,每次 heap 增加的值都会对齐到4KB。
2.malloc_state:
管理arena的一个结构,包括堆状态信息,bins链表等等
(1)main_arena
对应的malloc_state结构的全局指针存储在glibc的全局变量中
(如果可以泄露malloc_state结构体的地址,那么就可以泄露glibc的地址)
(2)per thread arena
对应的malloc_state存储在各自本身的arena
3.bins:
用链表结构管理空闲的chunk块,通过free释放进入的chunk块(垃圾桶)
4.chunks:
一般意义上的堆内存块
1 | #注释头 |
▲内存中的堆情况:
全局变量glibc:main_arena = struct malloc_state:
| mutes | bin | ….. | top | lastremainder |
|---|---|---|---|---|
| Allocated chunk | Allocated chunk | Freechunk1 | Allocated chunk | Freechunk2 | Allocated chunk | Topchunk |
|---|---|---|---|---|---|---|
低地址————————————————————- ——————>高地址
由sbrk创建的main_arena:
可以把bin也当作一个chunk,不同Bins管理结构不同,有单向链表管理和双向链表管理。
top里的bk保存Topchunk的首地址。
(bk和fd只用于Bins链表中,allocated_chunk中是属于用户可以使用的内容)
二、chunk结构:
1.chunk状态
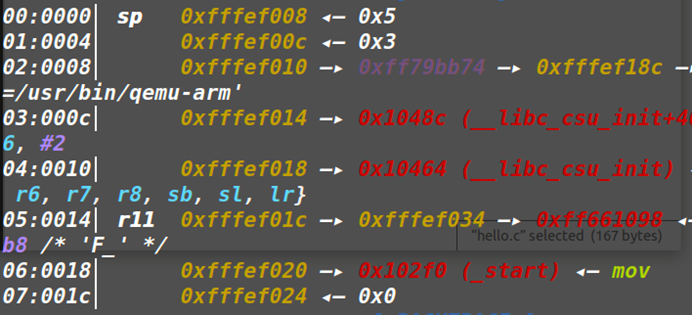
(1)allocated_chunk:
(2)free_chunk:
2.prev_size:
8字节,保存前一个chunk的大小,在allocatedchunk中属于用户数据,参考上述的图片,free_chunk的下一个chunk的pre_size位为该free_chunk的size。
3.size:
(1)size含义
8字节,保存当前chunk大小。(free和allocated都有用)一个chunk的size以0x10递增,以0x20为最小chunk。
malloc(0x01):会有0x20这么大,实际用户可用数据就是0x18。size=0x21
malloc(0x01-0x18):仍然0x20这么大,实际用户可用数据就是0x18。size=0x21
malloc(0x18):会有0x30这么大,实际用户可用数据是0x28。size=0x31
所以size这个8字节内存的最低4位都不会被用到,所以malloc管理机制给最低的3位搞了个特殊形式标志位,A,M,P,分别代表不同内容。
(2)AMP标志位
①A:NON_MAIN_ARENA
代表是否属于非main_arena,1表是,0表否。就是线程的不同。
1 | #注释头 |
②M:IS_MMAPPED
代表当前chunk是否是mmap出来的。
1 | #注释头 |
③P:PREV_INUSE
代表前一个chunk是否正在被使用,处于allocated还是free。
1 | #注释头 |
(标志位为1都代表是,0都代表否)
三、bins结构:
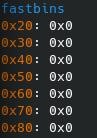
1.fastbins
放在struct malloc_state中的mfastbinptr fastbinsY[NFASTBINS]数组中。
(1)归类方式:
只使用fd位
bin的index为1,bins[0],bins[1]组成一个bin。
规定大小的chunk归到一类,但个数有限,不同版本不同,同时也可以设置其范围:
M_MXFAST即为其最大的参数,可以通过 mallopt()进行设置,但最大只能是80B。
(2)单向链表:
▲例子:a=malloc(0x10); b=malloc(0x10); c=malloc(0x10); d=malloc(0x10)
FastbinY,d,c,b,a
- free(a)之后:
1 | #注释头 |
- free(b)之后:
1 | #注释头 |
- free(c)之后:
1 | #注释头 |
- free(d)之后:
1 | #注释头 |
(3)后进先出:
m=malloc(0x10): m->d
n=malloc(0x10): n->c
(4)IN_USE位:
如果某个chunk进入到fastbin中,那么该chunk的下一个chunk的IN_USE位还是为1,不会改变成0。
例子:a=malloc(0x10); b=malloc(0x10); c=malloc(0x10);
free(a)之后: b.p=1
free(b)之后: c.p=1; b.p=1
p位不会变成0,如果该chunk进入到fastbins中。
可以进行free(0),free(1),free(0),但是不能直接free(0)两次。
(5)注意
除了malloc_consolidate函数会清空fastbins,以及在tcache下存在fastbin_reverseTo_tcache外,其它的操作都不会减少fastbins中chunk的数量。
2.smallbins:
放在bins[2]-bins[125]中,共计62组,是一个双向链表。最大chunk的大小不超过1024字节
(1)归类方式:
相同大小的chunk归到一类:大小范围[0x20,0x3f0],0x20、0x30、….0x3f0。每组bins中的chunk大小一定。
每组bin中的chunk大小有如下关系:Chunk_size=2 * SIZE_SZ * index,index即为2-63,下图中64即为largebins的范围了。(SIZE_SZ在32,64位下分别位4,8。)

(2)双向链表:
▲例子:a=malloc(0x100); b=malloc(0x100); c=malloc(0x100)
- free(a)之后: smallbin,a
1 | #注释头 |
- free(b)之后: smallbin,b,a
1 | #注释头 |
- free(c)之后: smallbin,c,b,a
1 | #注释头 |
(fd,bk为bins[n],bins[n+1]。fd和bk共同构成一个Binat。)
(3)先进先出:
m=malloc(0x100): m->a
n=malloc(0x100): n->b
3.largebins
放在bins[126]-bins[251],共计63组,bin的index为64-126,最小chunk的大小不小于1024个字节。
(1)归类方式:
范围归类,例如bins[126]-bins[127]中保存chunk范围在[0x400,0x440]。且chunk在一个bin中按照从大到小排序,便于检索。其它与smallbins基本一致。
①范围模式:
由以下代码定义范围:
1 | #注释头 |
②范围具体实例:
1 | #注释头 |
(2)双向链表:
①取用排列:
首先依据fd_nextsize,bk_nextsize两个指针大小找到适合的,然后按照正常的FIFO先进先出原则,通过fd,bk来排列。
②大小排列:
每个进入largebin的chunk
其chunk_addr+0x20处即为其fd_nextsize指针,chunk_addr+0x28处为其bk_nextsize指针。
然后通过fd_nextsize,bk_nextsize两个指针依据从大至小的顺序排列:
(这张图片我也忘记从哪里整的了…侵删)
其中size顺序为:D>C>B>A,但是释放顺序却不一定是这样的。设置这个的原因是当申请特定大小的堆块时,可以据此来快速查找,提升性能。
(3)特殊解链:
由于largebin中会存在fd_nextsize指针和bk_nextsize指针,所以通常的largebin_attack就是针对这个进行利用的。
借用星阑科技的一张图说明一切:
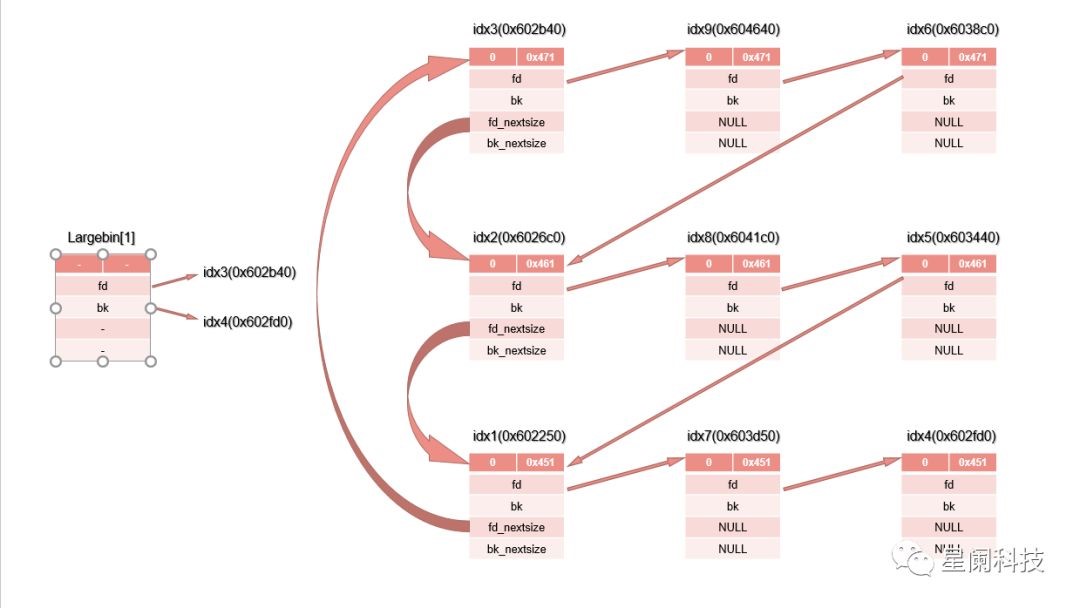
4.unsortedbins
bins[0]和bins[1]中,bins[0]为fd,bins[1]为bk,bin的index为1,双链表结构。
(1)归类方式:
只有一个bin,存放所有不满足fastbin,未被整理的chunk。
(2)双向链表:
a=malloc(0x100); b=malloc(0x100); c=malloc(0x100)
- free(a)之后: unsortedbin,a
1 | #注释头 |
- free(b)之后: unsortedbin,b,a
1 | #注释头 |
- free(c)之后: unsortedbin,c,b,a
1 | #注释头 |
(3)先进先出:
m=malloc(0x100): m->a
n=malloc(0x100): n->b
▲依据fd来遍历:
如果fd链顺序为A->B->C
那么解链顺序一定是先解C,再解B,再解A。
5、Tcache机制:
从libc-2.26及以后都有:先进后出,最大为0x410
(1)结构:
①2.29以下
无key字段的tcache,结构大小为0x240,包括chunk头则占据0x250:
1 | #注释头 |
counts:
是个数组,总共64个字节,对应tcache的64个bin,每个字节代表对应bin中存在chunk的个数,所以每个字节都会小于8,一般使用
1 | #注释头 |
来访问索引对应bin的count。

从0x55555555b010至0x55555555b04f都是counts这个数组的范围。
▲由于使用tcache时,不会检查tcache->counts[tc_idx]的大小是否处在[0,7]的范围,所以如果我们可以将对应bin的count改成[0,7]之外的数,这样下回再free该bin对应大小的chunk时,就不会将该chunk置入tcache中,使得tcache不满也能不进入tcache。
B.entries:是个bin指针数组,共64个指针数组,每个指针8个字节,总计大小0x200字节,指针指向对应的bin中第一个chunk的首地址,这个首地址不是chunk头的首地址,而是对应数据的首地址。如果该bin为空,则该指针也为空。一般会使用tcache->entries[tc_idx] != NULL来判断是否为空。
②2.29及以上
在entry中增加了key字段,结构体大小为0x290,count由原来的一个字节变为两个字节
1 | #注释头 |
(2)个数
类似于一个比较大的fastbins。总共64个bin。
(3)归类方式:
相同大小的chunk归到一类:大小范围[0x20,0x410]。每组bins中的chunk大小一定。且一组bin中最多只能有7个chunk,如果free某大小bin的chunk数量超过7,那么多余的chunk会按照没有tcache机制来free。
(4)单向链表:
▲例子:a=malloc(0x10); b=malloc(0x10); c=malloc(0x10); d=malloc(0x10)
FastbinY,d,c,b,a
free(a)之后:tcachebins[0x20]->a; a.fd=0
free(b)之后:tcachebins[0x20]->b; b.fd=a a.fd=0
free(c)之后:tcachebins[0x20]->c; c.fd=b b.fd->a; a.fd=0
free(d)之后:tcachebins[0x20]->d; d.fd=c c.fd->b; b.fd->a; a.fd=0
★但是这里的fd指向的是chunk内容地址,而不是其它的bins中的fd指向的是chunk头地址。
(5)后进先出
与fastbins类似。且tcache的优先级最高。
(6)特殊:
当tcache某个bin被填满之后,再free相同大小的bin放到fastbin中或者smallbins中,之后连续申请7个该大小的chunk,那么tcache中的这个bin就会被清空。之后再申请该大小的chunk就会从fastbins或者smallbins中找,如果找到了,那么返回该chunk的同时,会将该大小的fastbin或者smallbin中所有的chunk都移动到对应大小的tcache的bin中,直至填满7个。(移动时仍旧遵循先进后出的原则,所以移动之后chunk顺序会发生颠倒)
libc-2.26中存在tcache poisoning漏洞,即可以连续free(chunk)多次。
假如chunk0,chunk1,然后free(chunk0)两次,这样tcache bin中就是:
1 | chunk0.fd ->chunk0,即chunk0->chunk0 |
那么第一次申请回chunk0,修改fd为fakechunk,tcache bin中就是:
1 | chunk0.fd->fakechunk,即chunk0->fakechunk |
之后再申请回chunk0,再申请一次就是fakechunk了,实现任意地址修改。
★这个漏洞在libc2.27中就被修复了。
- 从tcache中申请Chunk的时候不会检查size位,不需要构造字节错位。
(7)2.31下新增stash机制:
在 Fastbins 处理过程中新增了一个 Stash 机制,每次从 Fastbins 取 Chunk 的时候会把剩下的 Chunk 全部依次放进对应的 tcache,直到 Fastbins 空或是 tcache 满。
(8)2.32下新增fd异或机制:
会将fd异或上某个值,这个具体看其他文章吧。
6.Topchunk:
不属于任何Bin,在arena中属于最高地址,没有其它空闲块时,topchunk就会被用于分配。
7.last_remainder:
当请求small chunk大小内存时,如果发生分裂,则剩余的chunk保存为last_remainder,放入unsortedbin中。
▲没有tcache的malloc和free流程:
四、malloc流程:
★如果是多线程情况下,那么会先进行分配区的加锁,这里就可能存在条件竞争漏洞。
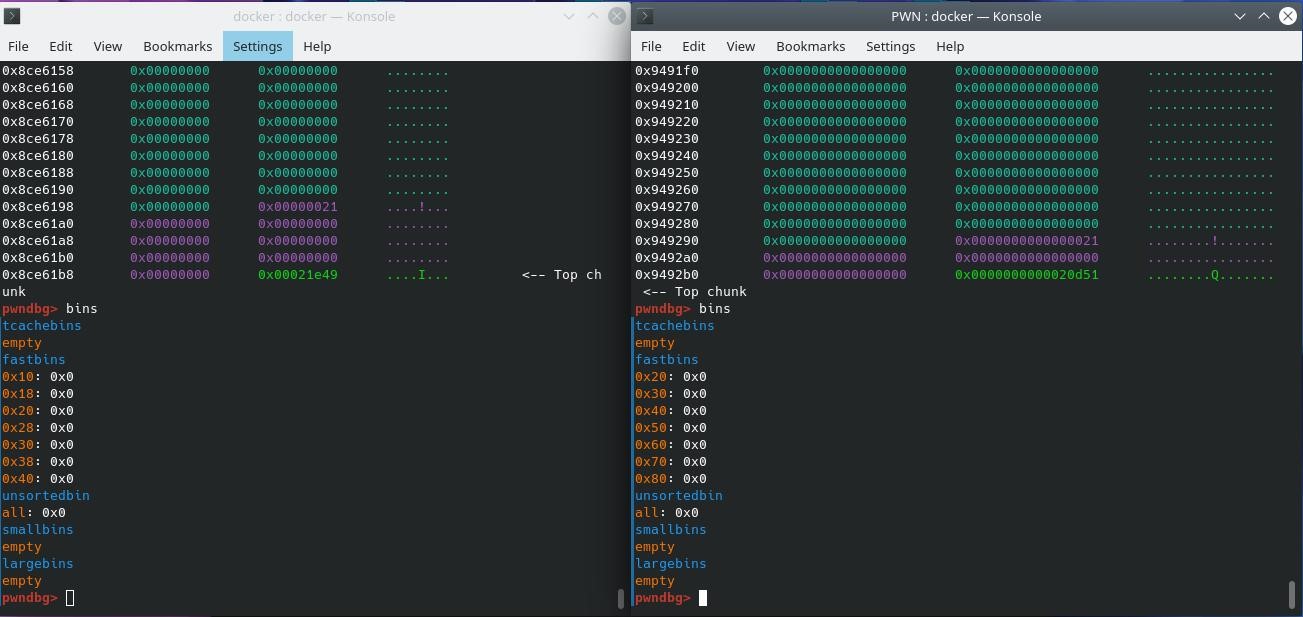
如果size在fastbins的范围内,则先在fastbins中查找,找到则结束,没找到就去unsortedbins中找。
如果size不在fastbins范围中,而在smallbins范围中,则查找smallbins(在2.23下如果发现smallbin链表未初始化,则会调用malloc_consolidate函数,但是实际情况在申请chunk之前都已经初始化过了,所以这个不怎么重要
1
if (victim == 0) /* initialization check */ malloc_consolidate (av);
而且这个操作从2.27开始已经没有了,如果能够让smallbin不初始化,或者将main_arena+0x88设置为0),此时若smallbin找到结束,没找到去unsortedbins中找
如果size不在fastbins,smallbins范围中,那一定在largebins中,那么先调用malloc_consolidate函数将所有的fastbin中的chunk取出来,合并相邻的freechunk,放到unsortedbin中,或者与topchunk合并。再去largebins中找,找到结束,没找到就去unsortedbins中找。
unsortedbins中查找:
- 如果unsortedbin中只有last_reaminder,且分配的size小于last_remainder,且要求的size范围为smallbin的范围,则分裂,将分裂之后的一个合适的chunk给用户,剩余的chunk变成新的last_remainder进入unsortedbin中。如果大于last_remainder,或者分配的size范围为largebin的范围,则将last_remainder整理至对应bin中,跳至第5步。
- 如果unsortedbin中不只一个chunk,则先整理,遍历unsortedbins。如果遇到精确大小,直接返回给用户,接着整理完。如果一直没遇到过,则该过程中所有遇到的chunk都会被整理到对应的fastbins,smallbins,largebins中去。
unsortedbins中找不到,则:
- 若当前size最开始判断是处于smallbins范围内,则再去smallbins找,这回不找精确大小,找最接近略大于size的一个固定大小的chunk给分裂,将符合size的chunk返回给用户,剩下的扔给unsortedbins,作为新的last_remainder。
- 若当前size最开始判断处于largebins范围内,则去largebins中找,和步骤(1)类似。
- 若当前size大于largebins中最大的chunk大小,那么就去topchunk来分割使用。
topchunk分割:
- topchunk空间够,则直接分割。
- topchunk空间不够,那么再调用malloc_consolidate函数进行整理一下,然后利用brk或者mmap进行再拓展。
- brk扩展:当申请的size小于128K时,使用该扩展。向高地址拓展新的topchunk,一般加0x21000,之后从新的topchunk再分配,旧的topchun进入unsortedbin中。
- mmap扩展:申请的size大于等于mmap分配阈值(最开始为128k)时,使用该扩展,但是这种扩展申请到的chunk,在释放时会调用munmap函数直接被返回给操作系统,而不会进入bins中。所以如果用指针再引用该chunk块时,就会造成segmentation fault错误。
▲当ptmalloc munmap chunk时,如果回收的chunk空间大小大于mmap分配阈值的当前值,并且小于DEFAULT_MMAP_THRESHOLD_MAX(32位系统默认为512KB,64位系统默认为32MB),ptmalloc会把mmap分配阈值调整为当前回收的chunk的大小,并将mmap收缩阈值(mmap trim threshold)设置为mmap分配阈值的2倍。这就是ptmalloc的对mmap分配阈值的动态调整机制,该机制是默认开启的,当然也可以用mallopt()关闭该机制
▲如果将 M_MMAP_MAX 设置为 0,ptmalloc 将不会使用 mmap 分配大块内存。
五、free流程:
★多线程情况下,free()函数同样首先需要获取分配区的锁,来保证线程安全。
首先判断该chunk是否为mmaped chunk,如果是,则调用 munmap()释放mmaped chunk,解除内存空间映射,该该空间不再有效。同时满足条件则调整mmap阈值。
如果size位于fastbins范围内,直接放到fastbins中。
如果size不在fastbins范围内,则进行判断:
- 先判断前一个chunk_before,如果chunk_before是free状态的,那么就将前一个chunk从其对应的bins中取出来(unlink),然后合并这两个chunk和chunk_before。由于还没有进入链表结构中,所以这里寻找chunk_before地址是通过当前地址减去当前chunk的presize内容,得到chunk_before的地址,从而获取其in_use位。
- 这也是presize唯一的用途,所以在堆溢出中,只要不进行free,presize可以任意修改。(这里如果chunk_before是位于fastbins中则没办法合并,因为在fastbins中的in_use位不会被改变,永远是1,在判断时始终认为该chunk是处于allocated状态的)
- 再判断后一个chunk,如果后一个chunk是free状态,那么如步骤(1),合并,之后将合并和的chunk放入到unsortedbins中去。如果后一个chunk就是topchunk,那么直接将这个chunk和topchunk合并完事。
- 之后将合并之后的chunk进行判断,(这里也可能不发生合并,但依旧会进行判断)如果size大于
FASTBIN_CONSOLIDATION_THRESHOLD(0x10000),那么就调用malloc_consolidate函数进行整理fastbins,然后给到unsortedbins中,等待malloc时进行整理。
▲32位与64位区别,差不多其实,对于0x8和0x10的变化而已: