2.29下的off-by-null
△相比2.29之前的版本中,在向上合并时加了一项检查:
1 | #注释头 |
就是检查上一个chunk的size是否等于当前chunk的pre_size。之前的off-by-null肯定是不等于的啊,所以这里就一定会出错。那么2.29的绕过方法就是通过smallbin和largebin来伪造一个chunk,满足:
1 | #注释头 |
其中③用来过新增加的检查:
1 | #注释头 |
①和②用来过unlink中的检查:
1 | #注释头 |
这样就能够成功off-by-null了,图示如下(用了t1an5g的博客的图片,侵删):
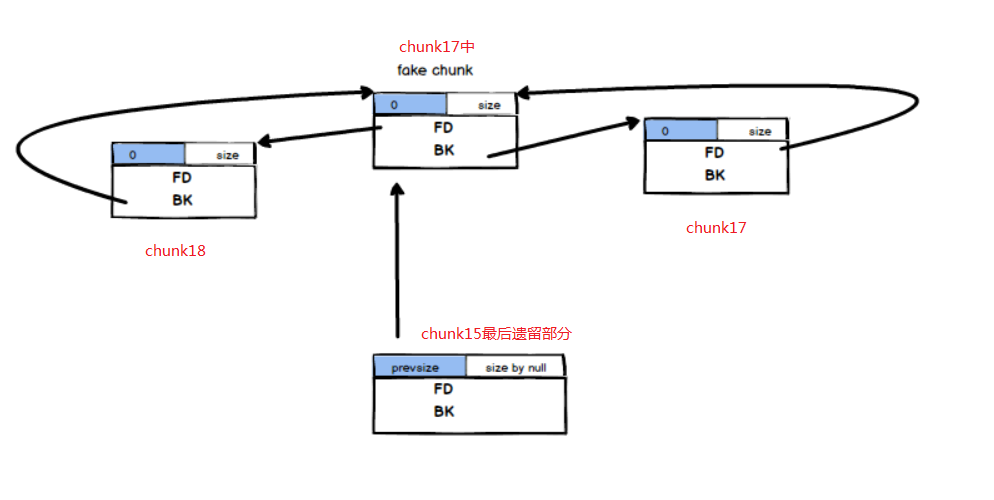
1.下面简单说下流程:
(1)进行一定的堆布局,使得起作用的chunk的堆地址为0xx…x0010,同时也方便计算偏移,从而进行低位字节覆盖。
(2)通过largebin的fd_nextsize指针和bk_nextsize指针,加上字节覆盖使得fake_chunk的fd指针指向指定FD(即下面的chunk18),fake_chunk的bk指针指向指定BK(即下面的chunk17)。
(3)通过fastbin和smallbin的连用,加上字节覆盖使得FD(chunk18)的bk指针指向fake_chunk。
(4)通过fastbin加上字节覆盖使得BK(chunk17)的fd指针指向fake_chunk。
(5)进行完以上操作就得到类似上图的堆布局,之后就可以绕过检查,触发off-by-null。
2.详细介绍一下具体实现方法:
(1)先申请17个chunk,chunk0-chunk16,其中chunk0-chunk7用来进行堆布局,使得后面的chunk15的地址为0xx..x0010,即使得申请的堆地址的第二个字节为”\x00”,以便之后覆盖的时候不用进行一字节爆破,从而进行对抗off-by-null的0字节溢出。当然,如果条件限制的话, 其实是可以不用chunk0-chunk7的布局,用一字节爆破来解决问题。chunk8-chunk14大小为0x28,用来填充0x30大小的tcache。chunk15即关键部分,chunk16防止合并。
(2)释放chunk15,size应该大于tcache的最大size,这里的chunk15最好设置大一点,大佬的博客设置了0xb20大小。然后chunk15就会进入unsortedbin中,由于unsortedbin中只有一个chunk15,所以chunk15的指针会有以下效果:
1 | #注释头 |
(3)申请一个0x28大小的chunk17,同时由于此时bin中没有chunk,只有Unsortedbin才有chunk15,所以会将chunk15先放入largebin中,之后再从chunk15中切割,返回chunk17,所以此时chunk15在largebin中,又只有它一个chunk,由于放入largebin的赋值语句,所以在切割之前会变成:
1 | #注释头 |
切割之后,chunk17获得了chunk15残留下来的fd,bk,fd_nextsize,bk_nextsize。因为chunk17是用来构造fake_chunk的,所以大小需要至少有0x20。那么此时的chunk17中内容就会如下:
1 | #注释头 |
然后构造在chunk17里制作fake_chunk,满足:
1 | #注释头 |
这里需要进行赋值:
1 | #注释头 |
(后面会讲到为什么会这么赋值)之后的fake_chunk的bk自动继承了之前残留下来的指针。
(4)申请chunk18-chunk21,大小为0x28。使得chunk18-chunk21都是从chunk15中切割出来的,之后用chunk8-chunk14填满0x30的tcache,然后再顺序释放chunk20和chunk18,使得chunk18,chunk20进入fastbin(0x30)中,顺序为chunk18->chunk20。
(5)将chunk8-chunk14申请出来,清空tcache(0x30),然后再申请一个0x400大小的chunk(超过smallbin大小即可),这样就会将fastbin中的chunk,也就是chunk18和chunk20放入到smallbin中。由于smallbin和fastbin刚好相反,一个是FIFO一个是FILO,所以顺序会反过来,变成:chunk20->chunk18,但同时由于是bk寻址,所以再申请chunk会先把chunk18取出来,同时在smallbin中,那么就会满足chunk18->bk == chunk20_addr
(6)此时赋值chunk18->bk = fake_chunk_addr,这里不用知道堆地址,因为我们知道chunk20_addr - fake_chunk_addr == 0x80(sizeof(fake_chunk)+sizeof(chunk18)+sizeof(chunk19))。所以之前chunk0-chunk7就可以进行一些大小布局,使得chunk15_addr == 0xx…x0010,那么fake_chunk_addr == 0xx…x0020,chunk20_addr == 0xx…x00a0,这样我们就只需要把0xa0覆盖成0x20,也就是修改chunk18->bk的第一个字节为0x20即可。但同时由于off by null的关系,修改chunk18->bk的第一个字节势必会导致第二个字节为”\x00”,所以我们之前的堆布局也要使得chunk15_addr的第二个字节为”\x00”才可以。
那么现在也可以理解之前的一个赋值语句:chunk17->fd_nextsize = “\x40”,这里就是为了将”\x10”覆盖为”\x40”使其指向chunk18,同时使得第二个字节也为”\x00”。
这样就满足了:
1 | #注释头 |
但是chunk17->fd不等于fake_chunk_addr。那么同样的操作再来一次,利用chunk17和chunk19,使其进入fastbin,将chunk17的fd指向chunk19,然后再申请回来,覆盖chunk17的fd指针,0x70覆盖为0x20即可。(由于2.29下的tcache会有key字段,使得chunk17的bk指针被修改,相当于修改fake_chunk的size位,这不是我们想看到的,所以还是用fastbin比较好)流程如下:
①将chunk20从tcache中申请出来,防止之后不好操作,然后再将chunk8-chunk14放入tcache中,使得之后的chunk进入fastbin。
②顺序释放chunk19,chunk17,使其进入fastbin中,使得chunk17->fd == chunk19_addr,就是0xx…x70。
③然后将chunk8-chunk14申请回来,再将chunk17申请回来,覆盖chunk17的fd的第一个字节为0x20,那么就可以满足总的条件:
1 | #注释头 |
(7)最后将chunk19申请回来,再从chunk15剩下的部分申请chunk22用来溢出。再申请chunk23将chunk15遗留的部分都申请回来,溢出之后释放掉,即可触发off by null,向上合并最初的chunk15-0x10大小的chunk,使得fake_chunk,chunk18,chunk19,chunk20,chunk21,chunk22,chunk23都被置入unsortedbin中。利用chunk8-chunk14对抗tcache,就可以随便玩了。(注意这里不需要像之前版本的off by null一样,还需要释放掉chunk0来绕过unlink检查,之前是因为不检查size位,所以直接释放掉即可。这里的fake_chunk已经替代了chunk0的作用,能够绕过Unlink的检查和size位的检查)
3.最后模拟一下代码,同样参考了大佬t1an5g的博客:
(1)前期准备加堆布局:
1 | #注释头 |
(2)制作fake_chunk,利用largebin踩下fd_nextsize和bk_nextsize:
1 | #注释头 |
(3)联动fastbin和smallbin:
1 | #注释头 |
(4)利用fastbin修改chunk17->fd:
1 | #注释头 |
(5)触发off-by-null:
1 | #注释头 |
△以上的chunk索引对于题目具体分析,不同题目对索引的处理肯定不一样。
其实还有其他只利用unsortedbin和largebin的绕过,贴一下地址:
https://www.anquanke.com/post/id/236078#h3-14
后面再来啃吧。