护网Web学习
偷溜来了护网,希望不会被逮住…..
▲其实决定来之前压根就不会Web,连HTML,CSS,PHP等等最基础的东西都不了解。决定要来之后,就抽空学了一些简单的实际渗透方面的Web利用,像之前写的永恒之蓝,sqlmap,nmap,Burpsuite,ARP啥的都是那一小段时间疯狂补的东西。然后期间经历了一点小插曲,本来以为不会来了,阴差阳错又过来了。和我一位学Web开发的傻嘚一起来的
一、HTML、CSS、PHP基础:
东西太杂,适当了解原理,以后即用即学。
二、XSS攻击:跨站脚本(Cross-Site Scripting)
四种类型,大概如下
1.原理解析:
(1)黑客通过某网站漏洞,将恶意代码注入到某网站中,生成类似图片,留言等进行伪装,内在是攻击链接。
(2)用户访问该网站,无意中点击了该图片,留言,那么就执行了这段恶意代码,进入了攻击链接,泄露信息。
2.例子:
(1)原网站的HTML:
1 | <!DOCTYPE html> |
后缀改为html,打开后如下:

(2)某些手段修改后如下:
1 | <!DOCTYPE html> |
打开后如下:

(3)攻击跳转
当不小心点到该图片后,会跳转到http://1.1.1.1/attack.php?Str这个URL界面,跳出如下界面:

其中array中就是访问该网站所得到的cookie令牌。
攻击者的attack.php代码如下:
1 | <?php |
攻击者将得到的cookie存储到他服务器1.1.1.1的xss.txt文件中,之后攻击者就可以利用从用户这得到的cookie来假装用户成功登录网站。
3.防御手段:
过滤输入,最有效的。
三、CSRF攻击:
跨站请求伪造(Cross-site request forgery)
1.原理解析:
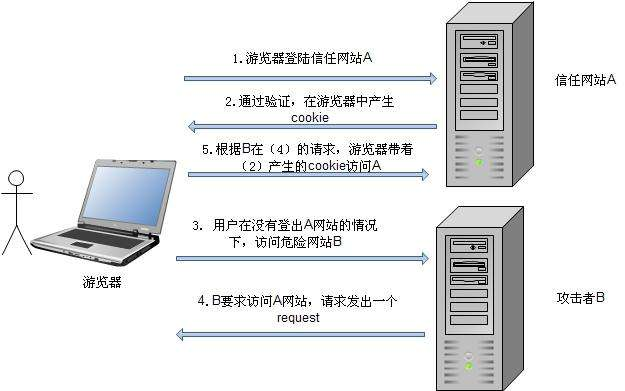
用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B,这个网站B就是黑客用来攻击的自己搭建的一个网站,或者是黑客插入攻击代码的网站;
访问网站B后,接收到用户请求后(黑客插入的链接或者是黑客自建的网站,前者需要用户点击恶意代码链接,类似于XSS攻击,后者则不需要),返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
▲简单来说就是利用恶意网站使得用户浏览器携带cookie和恶意代码请求来登录正常网站,这样黑客的恶意代码请求就可以在该网站被执行,从而使得黑客可以伪装成用户来执行任意操作,事后看到的也只是该用户的正常请求操作,基本没有什么攻击痕迹。
2.实例解析:
不搞了,DVWA上很多。
四、SSRF攻击:
Server-Side Request Forgery,服务端请求伪造
1.原理解析:
比较简单,常用来外网将服务器当跳板来探测内网。
利用服务器提供的功能,输入url获取图片,输入某ip查找信息等等。
构造我们需要的url,或者一些链接,服务来获取我们想要知道的信息。
2.实例解析:
不搞了,DVWA上很多。
后面有时间再总结下吧,得滚去补落下的东西了。
五、总结朔源:
首先得到ip,先挂clash和proxifier全局代理安排上。
IPIP.net ip138.com等查该ip下面绑了啥域名,对应开了什么web服务。
先Ping一下IP绑定的域名,看看最终的web服务是不是挂在该IP下。然后拿目录扫描器开始扫这个ip开的web服务,需要字典和工具。
根据扫描结果或经验,尝试看看能不能找到后台管理的登录页面,先尝试一波弱口令,SQL注入什么的。
现在就可以尝试分析这个Web服务的CMS架构,找出来之后就可以找对应版本漏洞打打试试,尝试拿Webshell。
经过艰苦不懈的尝试,再加上运气,可能就能拿Webshell了。这时候进入他的Web服务中,尝试提权什么的,一句话木马,各种小工具啥的上就完了。
搞了一堆也不太好使的话,那就可能要被发现了,这时候不要慌,走之前删一删Web服务上无关紧要的小图片,小链接什么的,然后尝试删记录退出啥的。
哎,这时候就可以打个游戏,吃个饭,睡个觉,第二天再来尝试看看,如果运气好没被堵上漏洞,那就看看日志,这兄弟的一些恢复操作就能完整被我们知道,然后根据这些日志来找账户密码,或者是一些系统操作调用啥的,方便我们拿到更高级的权限。
运气再好些拿到高权限的shell后,种个后门木马就跑路呗,记得删日志。
(像那种挂了很多域名,提供了看似正常的Web服务的,有很大可能是个用来翻墙洗白流量的服务器,这种服务器一般比较好拿权限,因为使用者一般挂完服务后都不会再投入过多精力去管的)
▲CMS啥的常规不管用,就扫端口,尝试端口服务漏洞直接爆破,再牛逼点,使用0day打。再再牛逼点,直接现场挖对应版本服务的漏洞(pwn大佬干的活)。
▲再补一下护网对USG写的脚本,是同学写的,版权在他那里,特此声明。本来自己想写另一个解析HTML的脚本却怎么也不成功,水平还是太差:
1 | #注释头 |
▲最后做个总结,学了这些天下来,感觉Web太杂太乱,边边角角太多,而且更新速度极快,可能过个一两个月就过时的,实在是不适合像我这种又蠢又懒,脑容量又小的菜鸡去搞。
还是感觉现在深入搞Web不到时候,在校期间更适合学些基础理论的东西,所以之后还是回老本行搞二进制去吧,起码这些理论知识更新换代比较慢一点。并且这种更新更像是一种基于理论来千变万化的,而不像Web好多都是那种一更新就完全变成新东西,没多少理论依据可言,直接就是开脑洞的。
还是搞二进制去吧,黑客的理想还是等以后工作了再来。